Отправить свою хорошую работу в базу знаний просто. Используйте форму, расположенную ниже
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
Размещено на http://www.allbest.ru/
Основные методы прогнозирования
Методы социального прогнозирования
Методы финансового прогнозирования
Методы экономического прогнозирования
Статистические методы прогнозирования
Экспертные методы прогнозирования
Анализ временных рядов
Структурные компоненты временного ряда
Основные методы прогнозирования
Прогнозирование - это предсказание будущего на основании накопленного опыта и текущих предположений относительно него.
Прогнозирование представляет собой сложный процесс, по ходу которого необходимо решать большое количество различных вопросов. Для его производства следует применять в сочетании различные методы прогнозирования , которых на сегодняшний день существует огромное множество, но на практике используются всего 15 - 20. На наиболее популярных из них мы и остановимся.
Метод экспертных оценок. Суть данного метода заключается в том, что в основе прогноза лежит мнение одного специалиста или группы специалистов, которое основано на профессиональном, практическом и научном опыте. Различают коллективные и индивидуальные экспертные оценки, часто используется при оценке персонала.
Метод экстраполяции. Основная идея экстраполяции - изучение сложившихся как в прошлом, так и настоящем стойких тенденций развития предприятия и перенос их на будущее. Различают прогнозную и формальную экстраполяцию. Формальная - основывается на предположении о том, что в будущем сохранятся прошлые и настоящие тенденции развития предприятия; при прогнозной - настоящее развитие увязывают с гипотезами о динамике предприятия с учетом того, что в будущем изменится влияние на него различных факторов. Следует знать, что методы экстраполяции лучше применять на начальной стадии прогнозирования, чтобы выявить тенденции изменения показателей.
Методы моделирования. Моделирование - это конструирование модели на основании предварительного изучения объекта и процессов, выделение его существенных признаков и характеристик. Прогнозирование с использованием моделей включает в себя ее разработку, экспериментальный анализ, сопоставление результатов предварительных прогнозных расчетов с фактическими данными состояния процесса или объекта, уточнение и корректировку модели.
Метод экономического прогнозирования (экономический анализ) заключается в том, что какой либо экономический процесс или явление, имеющие место на предприятии, расчленяются на части, после чего выявляется влияние и взаимосвязь этих частей на ход и развитие процесса, а также друг на друга. При помощи анализа можно раскрыть сущность такого процесса, а также определить закономерности его изменения в будущем, всесторонне оценить пути достижения поставленных целей. Поскольку экономический анализ - это необъемлемая часть и один из элементов логики прогнозирования, он должен осуществляться на макро-, мезо- и микроуровнях. Используется при планировании производства на предприятии. прогнозирование экономический временной экспертный
Процесс экономического анализа можно подразделить на несколько стадий:
* постановка проблемы, определение критериев оценки и целей;
* подготовка необходимой для анализа информации;
* аналитическая обработка информации после ее изучения;
* оформление результатов.
Балансовый метод. Данный метод основан на разработке балансов, которые представляют собой систему показателей, где первая часть, характеризующая ресурсы по источникам их поступления, равна второй, отражающей распределение их по всем направлениям расхода.
При помощи балансового метода воплощается в жизнь принцип пропорциональности и сбалансированности, который применяется при разработке прогнозов. Его суть заключается в увязке потребностей предприятия в различных видах сырьевых, материальных, финансовых и трудовых ресурсах с возможностями производства продукта и источниками ресурсов. Таким образом, система балансов, которую используют в прогнозировании, включает: финансовые, материальные и трудовые балансы. В каждую из данных групп входит еще ряд балансов.
Нормативный метод - один из основных методов прогнозирования. В настоящее время ему стало придаваться большое значение. Его сущность заключается в технико-экономических обоснованиях прогнозов с использованием нормативов и норм. Последние применяются при расчете потребности в ресурсах, а также показателей их использования.
Программно-целевой метод (ПЦМ). В сравнении с другими методами данный метод является сравнительно новым и недостаточно разработанным. Он начал широко применяться только в последние годы. ПЦМ тесно связан с уже рассмотренными методами и предполагает разработку прогноза начиная с оценки итоговых потребностей на основании целей развития предприятия при дальнейшем определении и поиске эффективных средств и путей их достижения, а также ресурсного обеспечения.
Суть ПМЦ заключается определении основных целей развития предприятия, разработки взаимосвязанных мероприятий по их достижению в заранее определенные сроки при сбалансированном обеспечении ресурсами, а также с учетом эффективного их использования.
Кроме прогнозирования, ПМЦ применяется при создании комплексных целевых программ, которые представляют собой документ, где отражены цель и комплекс производственных, организационно-хозяйственных, социальных и других мероприятий и заданий, увязанных по исполнителям, срокам осуществления и ресурсам.
Методы социального прогнозирования
Социальное прогнозирование как исследование с широким охватом объектов анализа опирается на множество методов. При классификации методов прогнозирования выделяются основные их признаки, позволяющие их структурировать по: степени формализации; принципу действия; способу получения информации.
Степень формализации в методах прогнозирования в зависимости от объекта исследования может быть различной; способы получения прогнозной информации многозначны, к ним следует отнести: методы ассоциативного моделирования, морфологический анализ, вероятностное моделирование, анкетирование, метод интервью, методы коллективной генерации идей, методы историко-логического анализа, написания сценариев и т.д. Наиболее распространенными методами социального прогнозирования являются методы экстраполяции, моделирования и экспертизы.
Экстраполяция означает распространение выводов, касающихся одной части какого-либо явления, на другую часть, на явление в целом, на будущее. Экстраполяция основывается на гипотезе о том, что ранее выявленные закономерности будут действовать в прогнозном периоде. Например, вывод об уровне развития какой-либо социальной группы можно сделать по наблюдениям за ее отдельными представителями, а о перспективах культуры - по тенденциям прошлого.
Экстраполяционный метод отличается многообразием - насчитывает не менее пяти различных вариантов. Статистическая экстраполяция - проекция роста населения по данным прошлого - это один из важнейших методов современного социального прогнозирования.
Моделирование - это метод исследования объектов познания на их аналогах - вещественных или мысленных.
Аналогом объекта может быть, например, его макет, чертеж, схема и т.д. В социальной сфере чаще используются мысленные модели. Работа с моделями позволяет перенести экспериментирование с реального социального объекта на его мысленно сконструированный дубликат и избежать риска неудачного, тем более опасного для людей управленческого решения. Главная особенность мысленной модели и состоит в том, что она может быть подвержена каким угодно испытаниям, которые практически состоят в том, что меняются параметры ее самой и среды, в которой она (как аналог реального объекта) существует. В этом огромное достоинство модели. Она может выступить и как образец, своего рода идеальный тип, приближение к которому может быть желательно для создателей проекта.
Самый практикуемый метод прогнозирования - экспертная оценка. По мнению Е.И.Холостовой, «экспертиза есть исследование трудноформализуемой задачи, которое осуществляется путем формирования мнения (подготовки заключения) специалиста, способного восполнить недостаток или несистемность информации по исследуемому вопросу своими знаниями, интуицией, опытом решения сходных задач и опорой на «здравый смысл».
Существуют такие сферы социальной жизни, в которых невозможно использовать другие методы прогнозирования , кроме экспертных. Прежде всего, это касается тех сфер, где отсутствует необходимая и достаточная информация о прошлом.
При экспертной оценке состояния либо отдельной социальной сферы, либо ее составляющего элемента, либо ее компонентов учитывается ряд обязательных положений, методических требований.
Прежде всего - оценка исходной ситуации:
Факторы, предопределяющие неудовлетворительное состояние;
Направления, тенденции, наиболее характерные для данного состояния ситуации;
Особенности, специфика развития наиболее важных составных;
Наиболее характерные формы работы, средства, с помощью которых осуществляется деятельность.
Второй блок вопросов включает в себя анализ деятельности тех организаций и служб, которые осуществляют эту деятельность. Оценка их деятельности идет по выявлению тенденций в их развитии, их рейтинга в общественном мнении.
Экспертную оценку проводят специальные центры экспертизы, научные информационно-аналитические центры, лаборатории экспертов, экспертные группы и отдельные эксперты.
Методика экспертной работы включает в себя ряд этапов:
Определяется круг экспертов;
Выявляются проблемы;
Намечается план и время действий;
Разрабатываются критерии для экспертных оценок;
Обозначаются формы и способы, в которых будут выражены результаты экспертизы (аналитическая записка, «круглый стол», конференция, публикации, выступления экспертов).
Итак, социальное прогнозирование опирается на различные методы исследования, основными из которых являются экстраполяция, моделирование и экспертиза.
Методы финансового прогнозирования
Финансовое прогнозирование по методу бюджетирования
Процесс бюджетирования является составной частью финансового планирования - процесса определения будущих действий по формированию и использованию финансовых ресурсов.
Бюджетирование - процесс построения и исполнения бюджета предприятия на основе бюджетов отдельных подразделений.
Бюджет - детализированный план деятельности предприятия на ближайший период, который охватывает доход от продаж, производственные и финансовые расходы, движение денежных средств, формирование прибыли предприятия.
Бюджеты подразделяются на два основных вида:
Операционный бюджет, отражающий текущую (производственную) деятельность предприятия;
Финансовый бюджет, представляющий собой прогноз финансовой отчетности.
План прибылей и убытков - основной документ операционного бюджета. Содержит данные о величине и структуре выручки от продаж, себестоимости реализованной продукции и конечных финансовых результатах.
Финансовый бюджет составляется с учетом информации, содержащейся в бюджете о прибылях и убытках.
Одним из основных этапов бюджетирования является прогнозирование движения денежных средств.
Бюджет движения денежных средств - это план денежных поступлений и платежей. При расчете бюджета движения денежных средств принципиально важно определить время поступлений и платежей, а не время исполнения хозяйственных операций.
Значение общего бюджета для предприятия раскрывается через следующие его функции:
Планирование операций, обеспечивающих достижение целей предприятия;
Координация различных видов деятельности и отдельных подразделений. Согласование интересов отдельных работников и групп в целом по предприятию;
Стимулирование руководителей всех рангов на достижение целей своих центров ответственности;
Контроль текущей деятельности, обеспечение плановой дисциплины;
Основа для оценки выполнения плана центрами ответственности и их руководителей;
Средство обучения менеджеров.
В отличие от формализованных отчетах о прибылях и убытках или бухгалтерского баланса, бюджет не имеет стандартизированной формы, которая должна строго соблюдаться. Бюджет может иметь бесконечное количество видов и форм. Форма и структура бюджета зависят от многих факторов: масштаба деятельности предприятия; достаточности и доступности исходной информации; состояния нормативной базы предприятия; от квалификации и опыта разработчика.
Финансовое прогнозирование по методу « процента от продаж
Существует два основнх метода финансового прогнозирования. Один из них - метод бюджетирования - представлен в разделе 3 методических указаний. Напомним, что он основан на концепции денежных потоков и его аналогом служит расчет финансовой части бизнес-плана.
Второй метод называется метод «процента от продаж» (первая модификация) или метод «формулы» (вторая модификация). Его преимущества - простота и лаконичность. Применяется для ориентировочных расчетов потребности во внешнем финансировании.
Факторы, оказывающие влияние на величину потребности в дополнительном финансировании:
Планируемый темп роста объема реализации;
Исходный уровень использования основных средств;
Капиталоемкость (ресурсоемкость) продукции;
Рентабельность продукции;
Дивидендная политика.
Метод «процента от продаж» - метод пропорциональной зависимости показателей деятельности предприятия от объема реализации.
Все вычисления по методу «процента от продаж» (методу «формулы») делаются на основе следующих предположений:
1. Переменные затраты, текущие активы и текущие обязательства при наращивании объема продаж на определенное количество процентов увеличиваются, в среднем, на столько же процентов. Это означает, что и текущие активы, и текущие пассивы будут составлять в плановом периоде прежний процент от выручки;
2. Процент увеличения стоимости основных средств рассчитывается под заданный процент наращивания оборота в соответствие с:
а) технологическими условиями бизнеса;
б) учетом наличия недогруженных основных средств на начало периода прогнозирования;
в) в соответствие со степенью материального и морального износа наличных основных средств и т.п.;
3. Долгосрочные обязательства и акционерный капитал берутся в прогноз неизменными;
4. Нераспределенная прибыль прогнозируется с учетом нормы распределения чистой прибыли на дивиденды и чистой рентабельности реализованной продукции.
Для прогнозирования нераспределенной прибыли к нераспределенной прибыли базового периода прибавляют прогнозируемую чистую прибыль и вычитают дивиденды.
Методы экономического прогнозирования
Особое место в классификации методов экономического прогнозирования занимают так называемые комбинированные методы, которые объединяют различные другие методы. Например, коллективные экспертные оценки и методы моделирования или статистические и опрос экспертов.
В качестве информации используется фактографическая и экспертная информация.
При классификации методов прогнозирования необходимо иметь в виду, что содержательная систематизация методов прогнозирования должна определяться самим объектом прогнозирования, экономическими процессами развития и их закономерностями.
С точки зрения оценки возможных результатов и путей прогнозного научно-технического развития прогнозы можно классифицировать по трем этапам: исследовательскому, программному и организационному.
Задачей исследовательского прогноза является определение возможных результатов будущего развития и выбор из множества возможных вариантов одного или нескольких положительных результатов. Так, например, развитие средств вычислительной техники можно отразить в росте их быстродействия, увеличении объема памяти и диапазона логических возможностей.
Основная цель этого этапа состоит в раскрытии широкой гаммы принципиально возможных перспектив в виде одной или ряда научно-технических проблем, подлежащих решению в течение прогнозируемого периода.
Программный аспект прогноза заключается в определении возможных путей достижения желаемых и необходимых результатов; ожидаемого по времени реализации каждого из возможных варианта и степени достоверности в успешном достижении некоторого результата по тому или иному варианту.
Организационная сторона прогноза включает в себя комплекс организационно-технических мероприятий, обеспечивающих достижение определенного результата по тому или иному варианту. В организационном аспекте исходят из представления о наличных экономических ресурсах и накопленном научном потенциале. Здесь должна быть сформулирована обоснованная гипотеза развития комплекса организационных параметров науки, дана вероятностная оценка рекомендуемой схеме распределения ресурсов и перспективам роста научного потенциала на прогнозируемый период.
Рассмотренные этапы научно-технического развития, как правило, выступают комплексно и находятся во взаимосвязи.
Статистические методы прогнозирования
Статистические методы прогнозирования охватывают разработку, изучение и применение современных математико-статистических методов прогнозирования на основе объективных данных (в том числе непараметрических методов наименьших квадратов с оцениванием точности прогноза, адаптивных методов, методов авторегрессии и других); развитие теории и практики вероятностно-статистического моделирования экспертных методов прогнозирования, в том числе методов анализа субъективных экспертных оценок на основе статистики нечисловых данных; разработку, изучение и применение методов прогнозирования в условиях риска и комбинированных методов прогнозирования с использованием совместно экономико-математических и эконометрических (как математико-статистических, так и экспертных) моделей. Научная база статистических методов прогнозирования -- прикладная статистика и теория принятия решений. Простейшие методы восстановления используемых для прогнозирования зависимостей исходят из заданного временного ряда, то есть функции, определенной в конечном числе точек на оси времени. При этом временной ряд часто рассматривается в рамках той или иной вероятностной модели, вводятся другие факторы (независимые переменные) помимо времени, напр., объем денежной массы. Временной ряд может быть многомерным. Основные решаемые задачи -- интерполяция и экстраполяция.
Метод наименьших квадратов в простейшем случае (линейная функция от одного фактора) был разработан К. Гауссом в 1794--1795 гг. Могут оказаться полезными предварительные преобразования переменных, например, логарифмирование. Наиболее часто используется метод наименьших квадратов при нескольких факторах.
Метод наименьших модулей, сплайны и другие методы экстраполяции применяются реже, хотя их статистические свойства зачастую лучше. Накоплен опыт прогнозирования индекса инфляции и стоимости потребительской корзины. Оказалось полезным преобразование (логарифмирование) переменной -- текущего индекса инфляции. Оценивание точности прогноза (в частности, с помощью доверительных интервалов) -- необходимая часть процедуры прогнозирования. Обычно используют вероятностно-статистические модели восстановления зависимости, напр., строят наилучший прогноз по методу максимального правдоподобия. Разработаны параметрические (обычно на основе модели нормальных ошибок) и непараметрические оценки точности прогноза и доверительные границы для него (на основе Центральной Предельной Теоремы теории вероятностей). Так, предложены непараметрические методы доверительного оценивания точки наложения (встречи) двух временных рядов для оценки динамики технического уровня собственной продукции и продукции конкурентов, представленной на мировом рынке. Применяются также эвристические приемы, не основанные на вероятностно статистической теории: метод скользящих средних, метод экспоненциального сглаживания.
Многомерная регрессия, в том числе с использованием непараметрических оценок плотности распределения, -- основной на настоящий момент статистический аппарат прогнозирования. Подчеркнем, что нереалистическое предположение о нормальности погрешностей измерений и отклонений от линии (поверхности) регрессии использовать не обязательно. Однако для отказа от предположения нормальности необходимо опереться на иной математический аппарат, основанный на многомерной Центральной Предельной Теореме теории вероятностей, технологии линеаризации и наследования сходимости. Он позволяет проводить точечное и интервальное оценивание параметров, проверять значимость их отличия от ноля в непараметрической постановке, строить доверительные границы для прогноза. Весьма важна проблема проверки адекватности модели, а также проблема отбора факторов. Априорный список факторов, оказывающих влияние на отклик, обычно весьма обширен. Его желательно сократить, и отдельное направление современных исследований посвящено методам отбора «информативного множества признаков». Однако эта проблема пока еще окончательно нерешена. Проявляются необычные эффекты. Так, установлено, что обычно используемые оценки степени полинома имеют в асимптотике геометрическое распределение. Перспективны непараметрические методы оценивания плотности вероятности и их применение для восстановления регрессионной зависимости произвольного вида. Наиболее общие результаты в этой области получены с помощью подходов статистики нечисловых данных. К современным статистическим методам прогнозирования относятся также модели авторегрессии, модель Бокса Дженкинса, системы эконометрических уравнений, основанные как на параметрических, так и на непараметрических подходах. Для установления возможности применения асимптотических результатов при конечных (т.н. «малых») объемах выборок полезны компьютерные статистические технологии. Они позволяют также строить различные имитационные модели. Отметим полезность методов размножения данных (бутстрепметодов). Системы прогнозирования с интенсивным использованием компьютеров объединяют различные методы прогнозирования в рамках единого автоматизированного рабочего места прогнозиста.
Прогнозирование на основе данных, имеющих нечисловую природу, например, прогнозирование качественных признаков основано на результатах статистики нечисловых данных. Весьма перспективными для прогнозирования представляются регрессионный анализ на основе интервальных данных, включающий, в частности, определение и расчет рационального объема выборки, а также регрессионный анализ нечетких данных. Общая постановка регрессионного анализа в рамках статистики нечисловых данных и ее частные случаи -- дисперсионный анализ и дискриминантный анализ (распознавание образов с учителем), -- давая единый подход к формально различным методам, полезны при программной реализации современных статистических методах прогнозирования. Основные процедуры обработки прогностических экспертных оценок -- проверка согласованности, кластер анализ и нахождение группового мнения.
Проверка согласованности мнений экспертов, выраженных ранжировками, проводится с помощью коэффициентов ранговой корреляции Кендалла и Спирмена, коэффициента ранговой конкордации Кендалла и Смита. Используются параметрические модели парных сравнений -- Терстоуна, БредлиТерриЛьюса -- и непараметрические модели теории люсианов. Полезна процедура согласования ранжировок и классификаций путем построения согласующих бинарных отношений. При отсутствии согласованности разбиение мнений экспертов на группы сходных между собой проводят методом ближайшего соседа или другими методами кластерного анализа (автоматического построения классификаций, распознавания образов без учителя). Классификация люсианов осуществляется на основе вероятностно-статистической модели. Используют также различные методы построения итогового мнения комиссии экспертов. Своей простотой выделяются методы средних арифметических и медиан рангов. Компьютерное моделирование позволило установить ряд свойств медианы Кемени, часто рекомендуемой для использования в качестве итогового (обобщенного, среднего) мнения комиссии экспертов в случае, когда их оценки даны в виде ранжировки.
Интерпретация закона больших чисел для нечисловых данных в терминах теории экспертного опроса такова: итоговое мнение устойчиво, т.е. мало меняется при изменении состава экспертной комиссии, и при росте числа экспертов приближается к «истине». При этом предполагается, что ответы экспертов можно рассматривать как результаты измерений с ошибками, все они -- независимые одинаково распределенные случайные элементы, вероятность принятия определенного значения убывает по мере удаления от некоторого центра -- «истины», а общее количество экспертов достаточно велико. В конкретных задачах прогнозирования необходимо провести классификацию рисков, поставить задачу оценивания конкретного риска, провести структуризацию риска, в частности, построить деревья причин (в другой терминологии, деревья отказов) и деревья последствий (деревья событий).
Центральной задачей является построение групповых и обобщенных показателей, например, показателей конкурентоспособности и качества. Риски необходимо учитывать при прогнозировании экономических последствий принимаемых решений, поведения потребителей и конкурентного окружения, внешнеэкономических условий и макроэкономического развития России, экологического состояния окружающей среды, безопасности технологий, экологической опасности промышленных и иных объектов. Современные компьютерные технологии прогнозирования основаны на интерактивных Статистические методы прогнозирования и использовании баз эконометрических данных, имитационных (в том числе на основе применения метода статистических испытаний) и экономико-математических динамических моделей, сочетающих экспертные, математико-статистические и моделирующие блоки.
Экспертные методы прогнозирования
Эксперт - квалифицированный специалист, привлекаемый для формирования оценок относительно объекта прогнозирования. Экспертная группа - коллектив экспертов, сформированный по определенным правилам. Суждение эксперта или экспертной группы относительно поставленной задачи прогноза называется экспертной оценкой; в первом случае используется термин «индивидуальная экспертная (прогнозная) оценка», а во втором - «коллективная экспертная (прогнозная) оценка». Способность эксперта создавать на базе профессиональных знаний, интуиции и опыта достоверные оценки относительно объекта прогнозирования характеризует его компетентность. Последняя имеет количественную меру, называемую коэффициентом компетентности. То же справедливо и в отношении экспертной группы: компетентность экспертной группы - это ее способность создавать достоверные оценки относительно объекта прогнозирования, адекватные мнению генеральной совокупности экспертов; количественная мера компетентности экспертной группы определяется на основе обобщения коэффициентов компетентности отдельных экспертов, входящих в группу.
Экспертный метод прогнозирования - метод прогнозирования, базирующийся на экспертной информации. В теоретическом аспекте правомерность использования экспертного метода подтверждается тем, что методологически правильно полученные экспертные суждения удовлетворяют двум общепринятым в науке критериям достоверности любого нового знания: точности и воспроизводимости результата. В таблице даны наименования и краткие характеристики основных экспертных методов, используемых при разработке социально-экономических прогнозов.
Анализ временных рядов
Цели, методы и этапы анализа временных рядов
Практическое изучение временного ряда предполагает выявление свойств ряда и получение выводов о вероятностном механизме, порождающем этот ряд. Основные цели при изучении временного ряда следующие:
Описание характерных особенностей ряда в сжатой форме;
Построение модели временного ряда;
Предсказание будущих значений на основе прошлых наблюдений;
Управление процессом, порождающим временной ряд, путем выборки сигналов, предупреждающих о грядущих неблагоприятных событиях.
Достижение поставленных целей возможно далеко не всегда как из-за недостатка исходных данных (недостаточная длительность наблюдения), так из-за изменчивости со временем статистической структуры ряда.
Перечисленные цели диктуют в значительной мере, последовательность этапов анализа временных рядов:
графическое представление и описание поведения ряда;
выделение и исключение закономерных, неслучайных составляющих ряда, зависящих от времени;
исследование случайной составляющей временного ряда, оставшейся после удаления закономерной составляющей;
построение (подбор) математической модели для описания случайной составляющей и проверка ее адекватности;
прогнозирование будущих значений ряда.
При анализе временных рядов используются различные методы, наиболее распространенными из которых являются:
корреляционный анализ, используемый для выявления характерных особенностей ряда (периодичностей, тенденций и т. д.);
спектральный анализ, позволяющий находить периодические составляющие временного ряда;
методы сглаживания и фильтрации, предназначенные для преобразования временных рядов с целью удаления высокочастотных и сезонных колебаний;
методы прогнозирования.
Структурные компоненты временного ряда
Как уже отмечалось, в модели временного ряда принято выделять две основные составляющие: детерминированную и случайную (рис.1). Под детерминированной составляющей временного ряда понимают числовую последовательность, элементы которой вычисляются по определенному правилу как функция времени t. Исключив детерминированную составляющую из данных, мы получим колеблющийся вокруг нуля ряд, который может в одном предельном случае представлять чисто случайные скачки, а в другом - плавное колебательное движение. В большинстве случаев будет нечто среднее: некоторая иррегулярность и определенный систематический эффект, обусловленный зависимостью последовательных членов ряда.
В свою очередь, детерминированная составляющая может содержать следующие структурные компоненты:
Тренд g, представляющий собой плавное изменение процесса во времени и обусловленный действием долговременных факторов. В качестве примера таких факторов в экономике можно назвать: а) изменение демографических характеристик популяции (численности, возрастной структуры); б) технологическое и экономическое развитие; в) рост потребления.
Сезонный эффект s, связанный с наличием факторов, действующих циклически с заранее известной периодичностью. Ряд в этом случае имеет иерархическую шкалу времени (например, внутри года есть сезоны, связанные с временами года, кварталы, месяцы) и в одноименных точках ряда имеют место сходные эффекты.
Размещено на Allbest.ru
...Подобные документы
Сущность экономического прогнозирования, характеристика основных форм предвидения. Предвидение внутренних и внешних условий деятельности. Виды прогнозов и технология прогнозирования. Методы прогнозирования: экспертные, статистические, комбинированные.
курсовая работа , добавлен 22.12.2009
Изучение методов прогнозирования развития: экстраполяции, балансового, нормативного и программно-целевого метода. Исследование организации работы эксперта, формирования анкет и таблиц экспертных оценок. Анализ математико-статистические моделей прогноза.
контрольная работа , добавлен 19.06.2011
Понятие, функции и методы прогнозирования – научно-обоснованного суждения о возможных состояниях объекта в будущем, об альтернативных путях и сроках их достижения. Классификация методов прогнозирования: социосинергетика, "коллективная генерация идей".
курсовая работа , добавлен 10.03.2011
Сущность основных понятий в области прогнозирования. Признаки классификации, виды прогнозов и их характеристика. Экстраполятивный и альтернативный подходы. Статистический и экспертный методы, их разновидности. Содержание и этапы разработки плана сбыта.
реферат , добавлен 25.01.2010
Сущность и структура системы социально-экономического прогнозирования, виды прогнозов и возможности их применения для предприятия. Мероприятия по планированию деятельности предприятия, их уровни и назначение. Экспертные методы, пути прогнозирования.
реферат , добавлен 27.06.2010
Суть форсайта как метода долгосрочного прогнозирования. Методы прогнозирования, применяемые в форсайтах. Критические технологии, экспертные панели. Особенности корпоративного форсайта. Применение метода корпоративных технологических "дорожных карт".
курсовая работа , добавлен 26.11.2014
Знакомство с основными проблемами прогнозирования, способы решения. Сглаживающие модели прогнозирования. Анализ подходов искусственного интеллекта: биологическая аналогия, архитектура сети, гибридные методы. Работа программы по прогнозу нейронных сетей.
дипломная работа , добавлен 27.06.2012
Методы прогнозирования, используемые в инновационном менеджменте. Шкалы и методы измерений в экспертном оценивании. Организация и проведение экспертизы. Получение обобщенной оценки на основе индивидуальных оценок экспертов, согласованность мнений.
курсовая работа , добавлен 07.05.2013
курсовая работа , добавлен 24.12.2011
Понятия прогнозирования и планирования. Почему прогнозировать сложно. Различные виды неопределенностей. Критерии классификации планирования. Основные техники и виды планирования. Основные методы прогнозирования. Планирование как управленческое решение.
Методы прогнозирования временных рядов
1. Прогнозирование как задача анализа временного ряда. Детерминированная и случайная составляющие: способы их выделения и оценки.
Прогнозирование – это научное выявление вероятностных путей и результатов предстоящего развития явлений и процессов, оценка показателей процессов для более или менее отдаленного будущего.
Изменение состояния наблюдаемого явления (процесса) характеризуется совокупностью параметров x1, x2, … , xt,…, измеренных в последовательные моменты времени. Такая последовательность называется временным рядом.
Анализ временных рядов – одно из направлений науки прогнозирования.
Если одновременно рассматриваются несколько характеристик процесса, то в этом случае говорят о многомерных временных рядах.
Под детерминированной (закономерной) составляющей временного ряда x1, x2, … , xn понимается числовая последовательность d1, d2, … , dn, элементы которой вычисляются по определенному правилу как функция времени t.
Если исключить из ряда детерминированную составляющую, то оставшаяся часть будет выглядеть хаотично. Ее называют случайной компонентой ε1, ε2, … , εn.
Модели разложения временного ряда на детерминированную и случайную компоненты:
1. Аддитивная модель:
xt = dt + εt, t=1,…n
2. Мультипликативная модель:
xt = dt · εt, t=1,…n
Если мультипликативную модель прологарифмировать, то получим аддитивную модель для логарифмов xt.
В детерминированной компоненте выделяют:
1) Тренд (trt) – плавно изменяющаяся нециклическая компонента, описывающая чистое влияние долговременных факторов, эффект которых сказывается постепенно.
2) Сезонная компонента (St) – отражает повторяемость процессов во времени.
3) Циклическая компонента (Ct) – описывает длительные периоды относительного подъема и спада.
4) Интервенция – существенное кратковременное воздействие на временной ряд.
Модели тренда:
– линейная: trt = b0 + b1t
– нелинейные модели:
полиномиальная: trt = b0 + b1t + b2t2 + … + bntn
логарифмическая: trt = b0 + b1 ln(t)
логистическая:
экспоненциальная: trt = b0 · b1t
параболическая: trt = b0 + b1t + b2t2
гиперболическая: trt = b0 + b1 /t
Тренд используется для долгосрочного прогноза.
Выделение тренда:
1) Метод наименьших квадратов (время – фактор, временной ряд – зависимая переменная):
xti = f (ti, θ)+εt i=1,…n
f – функция тренда;
θ – неизвестные параметры модели временного ряда.
εt – независимые и одинаково распределенные случайные величины.
Если минимизировать функцию, можно найти параметры θ.
2) Применение разностных операторов
![]()
Выделение сезонных эффектов
Пусть m – число периодов, p – величина периода.
St = St+p, для любых t.
1) Оценка сезонной компоненты
а) Сезонные эффекты на фоне тренда
Для аддитивной модели xt = trt + St + εt оценка:
Если необходимо, чтобы сумма сезонных эффектов равнялась 0, то переходят к скорректированным оценкам сезонных эффектов:

Для мультипликативной модели xt = trt * St * εt:

б) При наличии в ряде циклической компоненты (метод скользящих средних)
Идея метода: каждое значение исходного ВР заменяется средним значением на интервале времени, длина которого выбирается заранее. Выбранный интервал как бы скользит вдоль ряда.
Скользящее среднее при медианном сглаживании: t=med (xt-m,xt-m+1, …,xt+m)
При средне арифметическом сглаживании:
xt=1/(2m+1)(xt-m+xt-m+1+…+xt+m), если р – четный,
xt=1/(2m)(1/2*xt-m+xt-m+1+…+1/2*xt+m) если р – нечетный.
Для аддитивной модели xt = trt +Ct + St + εt.
Для упрощения обозначений: начнем нумерацию величин с единицы, изменим нумерацию исходного ряда так, чтобы величине x соответствовал член xt.
– скользящее среднее с периодом p, построенное по xt.
Для мультипликативной модели – перейти к логарифмам и получить мультипликативную модель.
xt = trt · Ct · St · εt
yt = log xt, dt = log trt, gt = log Ct, rt = log St, δt = log εt
yt = dt + gt + rt + δt
2) Удаление сезонной компоненты (сезонное выравнивание)
а) При наличии оценок сезонной компоненты:
Для аддитивной модели – путем вычитания из начальных значений ряда полученных сезонных оценок .
Для мультипликативной модели – путем деления начальных значений ряда на соответствующие сезонные оценки и умножением на 100%.
б) Применение разностных операторов
где В – оператор сдвига назад.
Разностный оператор второго порядка:
Если ВР одновременно содержит тренд и сезонную компоненту, то их удаление возможно с помощью последовательного применения простых и сезонных разностных операторов. Порядок их применения не существенен:
3) Прогнозирование с помощью сезонной компоненты:
Для аддитивной модели:
![]()
Для мультипликативной модели:

2. Модели временного ряда: AR(p), MA(q), ARIMA(p,d,q). Идентификация моделей, оценка параметров, исследование адекватности модели, прогнозирование.
Для описания вероятностной компоненты временного ряда используют понятие случайного процесса.
Случайным процессом x(t), заданным на множестве Т, называют функцию от t, значения которой при каждом t T являются случайной величиной.
Случайные процессы, у которых вероятностные свойства не изменяются во времени, называются стационарными (матожидание и дисперсия – константы).
В качестве модели стационарных временных рядов чаще всего используются:
Скользящее среднее;
Их комбинации.
Для проверки стационарности ряда остатков и оценки его дисперсии используют:
Выборочную автокорреляционную функцию (коррелограмму);
Частную автокорреляционную функцию.
Пусть εt – процесс белого шума, т.е. в разные моменты времени t случайные величины εt независимы и одинаково распределены с параметрами M(εt)=0, D(εt)=σ2=const. Тогда:
Случайный процесс x(t) со средним значением μ называется процессом авторегрессии порядка p (AR(p)), если для него выполняется соотношение:
x(t)-μ= α1 (x(t-1) – μ) + α2 (x(t-2) – μ) +…+ αp (x(t-p) – μ) + εt
Случайный процесс x(t) называется процессом скользящего среднего порядка q (MA(q)), если для него выполняется соотношение:
x(t)= εt + β1 εt-1 +…+ βq εt-q
Случайный процесс x(t) называется процессом авторегрессии-скользящего среднего порядков p и q (ARMA(p,q)), если для него выполняется соотношение:
Нестационарные технические и экономические процессы могут быть описаны модифицированной моделью ARMA(p,q). Для удаления тренда можно использовать разностные операторы.
Пусть даны две последовательности U=(…,U-1,U0,U1,…) и V=(…,V-1, V0,V1,V2,…) такие, что:
Означает ,для
![]() означает и т.д.
означает и т.д.
Тогда процесс AR(p) представляется в виде ,
MA(q): ![]() ,
,
ARMA(p,q): ![]()
B можно использовать как разностный оператор, т.е. ![]()
эквивалентно V=(1-B)U
Для разностей второго порядка:
z =(1-B)V=(1-B)2U

где – разностный оператор порядка d; x=(1-B)dx.
Идентифицировать модель – определить ее параметры p, d и q. Для идентификации модели служат графики частных автокорреляционных (АКФ) и частных автокорреляционных функций (ЧАКФ).
АКФ. k-й член АКФ определяется по формуле:
 (*)
(*)
Параметр k называют лагом. На практике k < n/4. График АКФ – коррелограмма. Если полученный ряд остатков нестационарный, то по коррелограмма можно определить причины нестационарности.
Значения ЧАКФ akk находят, решая систему Юла – Уолкера, используя значения АКФ
Система Юла – Уолкера:
R1 = a1 + a2*r1 + … + ap*rp-1
r2 = a1*r1 + a2 + … + ap*rp-2
………………………………..
rp = a1*rp-1 + a2*rp-2 + …+ ap
После визуализации ряда и удаления тренда рассматривается АКФ. Если график АКФ не имеет тенденции к затуханию, то это нестационарный процесс (модель ARIMA). При наличии сезонных колебаний коррелограмма содержит периодические всплески, как правило, соответствующие периоду колебаний. Рассматриваются разности 1-го, 2-го,…k-го порядка, пока ряд не станет стационарным, тогда параметр d=k (обычно k не больше 2). Переходят к идентификации стационарной модели.
Идентификация стационарных моделей:
АКФ плавно спадает;
ЧАКФ обрывается на лаге p.
АКФ обрывается на лаге q.
ЧАКФ плавно спадает.
Оценка параметров m, ai модели AR(p):
В качестве оценки m можно взять среднее значении ВР

Для оценки ai найдем корреляцию между X(t) и X(t-k):
Общее решение этого уравнения относительно rk определяется корнями характеристического уравнения
Пусть корни характеристического уравнения различны. Тогда общее решение может быть записано в виде:
Из требования стационарности следует, что все |λi|<1.
Если записать уравнение (**) для k=1, 2, 3…., получим систему Юла-Уоркера для AR(p) процесса:
r1 = a1 +a2*r1 + … + ap*rp-1
r2 = a1*r1 + a2 + … + ap*rp-2
………………………………..
rp = a1*rp-1 + a2*rp-2 + …+ap
Решая эту систему относительно a1, a2....ap, получим параметры AR(p).
Оценка параметра βi модели MA(q):
Для процесса МА(q) при |k| > q Cov = 0.
Cov = s2*(bk + b1*bk+1 + b2*bk+2 + … + bq-k*bq)
Отсюда автокорреляционная функция имеет вид:
 (***)
(***)
Для оценивания коэффициентов bi по наблюденному участку траектории существует несколько путей. Наиболее простой:
Находят
коэффициенты корреляции ![]() по формуле (*). Из
системы (***) получают систему нелинейных уравнений для нахождения bi. Она решается
итерационными методами.
по формуле (*). Из
системы (***) получают систему нелинейных уравнений для нахождения bi. Она решается
итерационными методами.
Прогнозирование. При прогнозировании необходимо получить детерминированные значения ВР по уже имеющимся формулам, а затем рассчитать случайные значения по подобранной модели и скорректировать детерминированные значения на величину случайных значений.
3. Прогнозирование с помощью искусственных нейронных сетей, метод окон.
Решение математических задач с помощью нейронных сетей (НС) осуществляется путем обучение НС способам решения этих задач.
Обучение многослойной нейронной сети производится методом обратного распространения ошибки (Back Propagation).
Модель искусственного нейрона
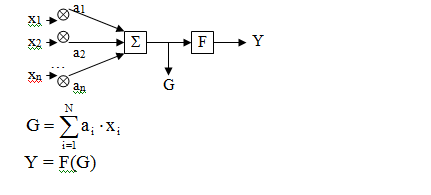
где xi – входные сигналы,
ai – коэффициенты проводимости (const), которые корректируются в процессе обучения,
F – функция активации, она нелинейная, в разных моделях может называться по-разному. Например, «сигмоида»:
Общая структура нейронной сети:

Скрытых слоев может быть несколько, поэтому НС – многослойная.
– вектор эталонных сигналов (желаемых)
yi – вектор реальных (выходных) сигналов
xi – вектор входных сигналов.
Стратегия обучения «обучение с учителем»
Типовые шаги:
1) Выбрать очередную обучающую пару из обучающего множества .
x – входной вектор;
– соответствующий ему желаемый (выходной вектор).
Подать входной вектор х на вход НС.
2) Вычислить выход сети у – реальный выходной сигнал.
Предварительно, весовые коэффициенты aij и bij задаются произвольно случайным образом.
3) Вычислить отклонение (ошибку): ![]()
4) Подкорректировать веса aij и bij сети так, чтобы минимизировать ошибку.
![]()
5) Повторить шаги 1– 4.
Процесс повторяется до тех пор, пока ошибка на всем обучающем множестве не уменьшится до требуемой величины.
Проход вперед сигнала X по сети:
Из обучающего множества берется пара. Для каждого слоя, начиная с первого, вычисляется Y: Y = F(X·A),
где A – матрица весов слоя;
F – функция активации.
Вычисления – слой за слоем.
Обратный проход ошибки по НС:
Выполняется подстройка весов выходного слоя. Для этого применяется модифицируемое дельта-правило.
Рис. Обучение одного веса от нейрона p в скрытом слое j к нейрону q в выходном слое k
Для выходного нейрона сначала находится сигнал ошибки
![]()
εq умножается на производную сжимающей функции , вычисленную для этого нейрона слоя k. Получаем величину δ:
Δapqk = α · δqk · ypj,
где α – коэффициент скорости обучения (0.01≤ α <1) – const, подбирается экспериментально в процесса обучения.
ypj – выходной сигнал нейрона p слоя j.
 – величина веса в
связке нейронов p→q на шаге t (до
коррекции) и шаге t+1 (после коррекции).
– величина веса в
связке нейронов p→q на шаге t (до
коррекции) и шаге t+1 (после коррекции).
Подстройка весов скрытого слоя.
Рассмотрим нейрон скрытого слоя p. При переходе вперед этот нейрон передает свой выходной сигнал нейронам выходного слоя через соединяющие их веса. Во время обучения эти веса функционируют в обратном порядке, пропуская величину δ от выхода назад к скрытому слою.

И так для каждой пары. Процесс заканчивается, если для каждого X НС будет вырабатывать
Прогнозирование с помощью НС. Метод окон.
Задан временной ряд xt, t=1,2…T. Задача прогнозирования сводится к задаче распознавания образов на НС.
Метод выявления закономерности во временном ряде на основе НС называется “windowing” (метод окон).
Используется два окна Wi (input) и Wo (output) фиксированного размера n и m соответственно, для наблюдаемого множества данных.

Эти окна способны перемещаться с некоторым шагом S по кривой (ряду) вдоль оси времени. В результате получается некоторая последовательность наблюдений:

Первое окно Wi, сканирует данные, предает их на вход НС, а Wo – на выход. Получающаяся на каждом шаге пара Wji→Wj0, j=1..n образует обучающую пару (наблюдение). После обучения НС можно использовать для прогноза.
Всем привет, раз на хабре пошел цикл статей про нейронные сети, то и я напишу про возможность использования нейронных сетей в задаче прогнозирования финансовых временных рядов.Существует несколько различных теорий о возможности прогнозирования фондовых рынков. Одна из них - гипотеза эффективного рынка, согласно ей, в цене акции уже учтена вся имеющиеся информация и делать прогнозы бессмысленно. Продолжением этой гипотезы можно назвать теорию случайных блужданий.
В теории случайных блужданий информация подразделяется на две категории - предсказуемую, известную и новую, неожиданную. Если предсказуемая, а тем более уже известная информация уже заложена в рыночные цены, то новая неожиданная информация в цене пока еще не присутствует. Одним из свойств непредсказуемой информации является ее случайность и, соответственно, случайность последующего изменения цены. Гипотеза эффективного рынка объясняет изменение цен поступлениями новой неожиданной информации, а теория случайных блужданий дополняет это мнением о случайности изменения цен.
Краткий практический вывод теории случайных блужданий - игрокам рекомендуется использовать в своей работе стратегию «покупай и держи». Следует заметить, что расцвет теории случайных блужданий пришелся на 70-е годы, когда на фондовом рынке США, традиционно являющемся главным полигоном проверки и использования всех новых экономических теорий, не было явных тенденций, а сам рынок находился в узком коридоре. Согласно гипотезе эффективного рынка и теории случайных блужданий прогнозирование цен невозможно.
Однако, большинство участников рынка все же использует различные методы для прогнозирования, предполагая, что сам ряд полон скрытых закономерностей.
Такие скрытые эмпирические закономерности пытался выявить в 30-х годах в серии своих статей основатель технического анализа Эллиот (R.Elliott).
В 80-х годах неожиданную поддержку эта точка зрения нашла в незадолго до этого появившейся теории динамического хаоса. Эта теория построена на противопоставлении хаотичности и стохастичности (случайности). Хаотические ряды только выглядят случайными, но, как детерминированный динамический процесс, вполне допускают краткосрочное прогнозирование. Область возможных предсказаний ограничена по времени горизонтом прогнозирования, но этого может оказаться достаточно для получения реального дохода от предсказаний (Chorafas, 1994). И тот, кто обладает лучшими математическими методами извлечения закономерностей из зашумленных хаотических рядов, может надеяться на большую норму прибыли - за счет своих менее оснащенных собратьев.
Методы прогнозирования
В настоящее время профессиональные участники рынка используют различные методы прогнозирования финансовых временных рядов, основные из них:1) экспертные методы прогнозирования.
Самый распространенный метод из группы экспертных методов - метод Дельфи. Суть метода заключается в сборе мнений различных экспертов и их обобщение в единую оценку. Если мы прогнозируем этим методом финансовые рынки, то нам нужно выделить экспертную группу людей разбирающихся в этой предметной области (это могут быть аналитики, профессиональные трейдеры, инвесторы, банки итд), провести анкетирование или опрос и сделать обобщение о текущей ситуации на рынке.
2) Методы логического моделирования.
Основаны на поиске и выявлении закономерностей рынка в долгосрочной перспективе.
Сюда входят методы:
- метод сценариев («если - то»), описание последовательностей исходов из того или иного события, с созданием базы знаний;
- методы прогнозов по образу;
- метод аналогий.
3) Экономико-математические методы.
Методы из этой группы базируются на создании моделей исследуемого объекта. Экономико-математическая модель - это определенная схема, путь развития рынка ценных бумаг при заданных условиях. При прогнозировании финансовых временных рядов используют статистические, динамические, микро- макро-, линейные, нелинейные, глобальные, локальные, отраслевые, оптимизационные, дескриптивные. Очень значимы для финансовых наук оптимизационные модели, они представляют из себя систему уравнений, куда входят различные ограничения, а также особое уравнение называемое функционалом оптимальности (или критерием оптимальности). С помощью него находят оптимальное, наилучшее решение по какому-либо показателю.
4) Статистические методы.
Статистические методы прогнозирования применительно, для финансовых временных рядов основаны на построении различных индексов (диффузный, смешанный), расчет значений дисперсии, мат ожидания, вариации, ковариации, интерполяции, экстраполяции.
5) Технический анализ.
Прогнозирование изменений цен в будущем на основе анализа изменений цен в прошлом. В его основе лежит анализ временны́х рядов цен - «чартов» (от англ. chart). Помимо ценовых рядов, в техническом анализе используется информация об объёмах торгов и другие статистические данные. Наиболее часто методы технического анализа используются для анализа цен, изменяющихся свободно, например, на биржах. В техническом анализе множество инструментов и методов, но все они основаны на одном предположении: из анализа временны́х рядов, выделяя тренды, можно спрогнозировать поведение цен.
6) Фундаментальный анализ.
Метод прогнозирования рыночной (биржевой) стоимости компании, основанных на анализе финансовых и производственных показателей её деятельности.
Фундаментальный анализ используется инвесторами для оценки стоимости компании (или её акций), которая отражает состояние дел в компании, рентабельность её деятельности. При этом анализу подвергаются финансовые показатели компании: выручка, EBITDA (Earnings Before Interests Tax, Deprecation and Amortization), чистая прибыль, чистая стоимость компании, обязательства, денежный поток, величина выплачиваемых дивидендов и производственные показатели компании.
Использование нейронных сетей для прогнозирование финансовых временных рядов
Нейронные сети можно отнести к методам технического анализа, т.к они тоже пытаются выявить закономерности в развитие ряда, обучаясь на его исторических данных.Финансовый временной ряд довольно сильно зашумлен и поэтому надо уделить особое внимание предобработке данных и кодированию переменных.
Рис. 1 - Интервальный график в виде японских свечей индекса РТС. Период - день.
Для справки: каждая фигура на графике показывает нам определенный промежуток времени (в данном случае один день) и движения цены за этот промежуток. Опишем их:
- цена открытия - это величина цены в начале этого промежутка времени
- цена закрытия - это величина цены в конце этого промежутка времени
- максимальная цена - это максимальная цена за весь этот промежуток времени
- минимальная цена - это минимальная цена за весь этот промежуток времени
- если цена шла вверх (бычий тренд) за этот период - тело свечи будет белым (или прозрачным)
- если цена шла вниз (медвежий тренд) за этот период - тело свечи будет черным (или закрашенным) 
Рис. 2 - Японские свечи.
Действительно значимыми для предсказаний являются изменения котировок. Поэтому на вход нейронной сети после предварительной обработки будем подавать ряд процентных приращений котировок, рассчитанных по формуле X[t] / X, где X[t] и X цены закрытия периодов. 
Рис. 3 - Ряд процентных приращений котировок, рассчитанных по формуле X[t] / X.
Но, т.к. изначально процентные приращения имеют гауссово распределение, а из всех статистических функций распределения, определенных на конечном интервале, максимальной энтропией обладает равномерное распределение, то для этого перекодируем входные переменные, чтобы все примеры в обучающей выборке несли примерно одинаковую информационную нагрузку.
Рис. 4 - Распределение процентных приращений котировок.
Алгоритм здесь следующий - отрезок от минимального процентного приращения до максимального разбивается на N отрезков, так, чтобы в диапазон значений каждого отрезка входило равное количество процентных приращений котировок.
Рис. 5 - Границы 6 отрезков, количество процентных приращений в каждом отрезке равно.
Далее перекодируем процентные приращения в классы, идентифицирующие каждый отрезок.
Рис. 6 - Перекодирование процентных приращений.
И получим равномерное распределение.
Рис. 7 - Равномерное распределение.
Задача получения входных образов для формирования обучающего множества в задачах прогнозирования временных рядов предполагает использование метода «окна». Этот метод подразумевает использование «окна» с фиксированным размером, способного перемещаться по временной последовательности исторических данных, начиная с первого элемента, и предназначены для доступа к данным временного ряда, причем «окно» размером N, получив такие данные, передает на вход нейронной сети элементы с 1 по N-1, а N-ый элемент используется в качестве выхода.
Рис. 8 - Метод «окна».
Качество обучающей выборки тем выше, чем меньше ее противоречивость и больше повторяемость. Для задач прогнозирования финансовых временных рядов высокая противоречивость обучающей выборки является признаком того, что способ описания выбран неудачно. Факторы влияющие на противоречивость и повторяемость:
1) количество элементов обучающей выборки - чем больше элементов, тем больше противоречивость и повторяемость;
2) количество классов на которые перекодировали процентные приращения - при увеличение снижается противоречивость и повторяемость;
3) глубина погружения в финансовый временной ряд («окно») - чем больше глубина, тем меньше противоречивость и меньше повторяемость.
При создании обучающей выборки, меняя эти параметры, необходимо найти баланс при котором уровень противоречивости минимален а повторяемость максимальна.
Для практического примера спрогнозируем направления приращений индекса РТС с 16.01.2012 по 17.04.2012 гг, период - день.
Рис. 9 - График индекса РТС с 8.01.2012 по 18.04.2012 гг, период - день.
Создадим коллекцию нейронных сетей, показавших наилучшие результаты (более 70% правильно спрогнозированных направлений изменений значения индекса) на тестовом множестве (последние 50 периодов). Через каждые 5 периодов коллекция пересоздается, в тестовое множество включается уже прогнозированные периоды. Нейронные сети, входящие в коллекцию не однотипны - у каждой подбирается размер обучающей выборки, количество классов на которые перекодируются процентные приращения, глубина погружения («окно») и количество нейронов в скрытом слое так, чтобы наиболее точно прогнозировала текущую рыночную ситуацию (последние 50 периодов).
Базовая архитектура используемых нейронных сетей - многослойный перцептрон с одним скрытым слоем. Есть прекрасная готовая реализация в библиотеке ALGLIB . В качестве алгоритма обучения используем L-BFGS алгоритм (limited memory BFGS), квази-Ньютоновский метод с трудоемкостью итерации, линейной по количеству весовых коэффициентов WCount и размеру обучающего множества, и умеренными требованиями к дополнительной памяти - O(WCount).
Пример коллекции:
Прогноз с: 16.01.2012 по: 20.01.2012
Количество сетей: 16
Параметры сетей:
Вход: 3 Скрытый слой: 18 Количество классов: 4 Длина обучающей выборки: 200 Результат на об. выб.: 74,6 Результат на тестовой выб.: 72,5
Вход: 3 Скрытый слой: 19 Количество классов: 4 Длина обучающей выборки: 200 Результат на об. выб.: 74,6 Результат на тестовой выб.: 72,5
Вход: 3 Скрытый слой: 20 Количество классов: 4 Длина обучающей выборки: 200 Результат на об. выб.: 74,6 Результат на тестовой выб.: 72,5
Вход: 4 Скрытый слой: 18 Количество классов: 4 Длина обучающей выборки: 200 Результат на об. выб.: 75,6 Результат на тестовой выб.: 74,5
Вход: 4 Скрытый слой: 20 Количество классов: 4 Длина обучающей выборки: 200 Результат на об. выб.: 74,1 Результат на тестовой выб.: 72,5
Вход: 5 Скрытый слой: 19 Количество классов: 4 Длина обучающей выборки: 200 Результат на об. выб.: 74,6 Результат на тестовой выб.: 70,6
Вход: 5 Скрытый слой: 20 Количество классов: 4 Длина обучающей выборки: 200 Результат на об. выб.: 76,1 Результат на тестовой выб.: 72,5
Вход: 4 Скрытый слой: 18 Количество классов: 5 Длина обучающей выборки: 200 Результат на об. выб.: 67,2 Результат на тестовой выб.: 74,5
Вход: 5 Скрытый слой: 18 Количество классов: 5 Длина обучающей выборки: 200 Результат на об. выб.: 70,6 Результат на тестовой выб.: 74,5
Вход: 5 Скрытый слой: 19 Количество классов: 5 Длина обучающей выборки: 200 Результат на об. выб.: 76,6 Результат на тестовой выб.: 74,5
Вход: 5 Скрытый слой: 20 Количество классов: 5 Длина обучающей выборки: 200 Результат на об. выб.: 76,1 Результат на тестовой выб.: 74,5
Вход: 3 Скрытый слой: 18 Количество классов: 4 Длина обучающей выборки: 270 Результат на об. выб.: 74,9 Результат на тестовой выб.: 70,6
Вход: 3 Скрытый слой: 19 Количество классов: 4 Длина обучающей выборки: 270 Результат на об. выб.: 74,9 Результат на тестовой выб.: 70,6
Вход: 3 Скрытый слой: 20 Количество классов: 4 Длина обучающей выборки: 270 Результат на об. выб.: 74,9 Результат на тестовой выб.: 70,6
Вход: 5 Скрытый слой: 18 Количество классов: 4 Длина обучающей выборки: 340 Результат на об. выб.: 78,0 Результат на тестовой выб.: 70,6
Вход: 5 Скрытый слой: 19 Количество классов: 4 Длина обучающей выборки: 340 Результат на об. выб.: 79,5 Результат на тестовой выб.: 74,5
Параметры всех использованных коллекций можно посмотреть в файле
Так как прогнозируем направление изменения индекса РТС, то используем простейшую стратегию - открываем позицию по цене закрытия текущего периода и закрываем ее по цене закрытия прогнозируемого периода, фиксируя прибыль или убыток.
Рис. 10 - Результат работы.
Результат работы с 16.01.2012 по 17.04.2012 гг: 77% правильно прогнозированных направлений изменений значения индекса.
Теги:
- нейронные сети
- фондовый рынок
Транскрипт
1 Лабораторная работа 10. Прогнозирование временных рядов. Цель работы: Построение прогноза временного ряда несколькими способами и выбор лучшей модели прогнозирования. Нужно сделать Взять 2 временных ряда -- один в виде отдельного файла, другой из документа Excel Провести корреляционный анализ каждого временного ряда построить его график, рассчитать АКФ, построить график АКФ, определить свойства ряда Построить прогнозы заданных временных рядов несколькими различными способами. Модели временных рядов выбирать из текста лекции. Оценить ошибки прогнозирования и на основании рассчитанных ошибок выбрать наилучшую модель прогнозирования. К отчету Документ Mathematica с отчетами. Анализ и прогнозирование временных рядов Введение Прогнозирование одна из самых востребованных задач бизнес-аналитики. Продажи, поставки, заказы это процессы, распределенные во времени, следовательно, прогнозирование в области продаж, сбыта и спроса, управления материальными запасами и потоками обычно связано именно с анализом временных рядов. Временной ряд последовательность наблюдений за изменениями во времени значений параметров некоторого объекта или процесса. Временные отсчеты значения, зафиксированные в некоторые, обычно равноотстоящие моменты времени. В задачах анализа временных рядов мы имеем дело с дискретным временем, когда каждое наблюдение за параметром образует временной отсчет. Все временные отсчеты нумеруются в порядке возрастания. Тогда временной ряд будет представлен в виде X={x 1,x 2,x n }. Одномерные временные ряды содержат наблюдения за изменением только одного параметра исследуемого процесса или объекта, а многомерные за двумя параметрами или более. Например, трехмерный временной ряд, содержащий наблюдения за тремя параметрами X,Y,Z процесса F можно записать в следующем виде Цели и задачи анализа временных рядов F={(x 1,y 1,z 1), (x 2,y 2,z 2),(x n,y n,z n)} Описание характеристик и закономерностей ряда Моделирование построение модели исследуемого процесса Прогнозирование предсказание будущих значений временного ряда
2 Управление. Зная свойства временных рядов, можно выработать воздействия на соответствующие бизнес-процессы для управления ими методы Детерминированная и случайная составляющая временного ряда Закономерная (детерминированная) составляющая временного ряда последовательность значений, элементы которой могут быть вычислены в соответствии с определенной функцией. Закономерная составляющая временного ряда отражает действие известных факторов и величин. Зная функцию, описывающую закономерность, в соответствии с которой развивается исследуемый процесс, мы можем вычислить значение детерминированной составляющей в любой момент времени. Случайная (стохастическая) составляющая временного ряда последовательность значений, которая является результатом воздействия на исследуемый процесс случайных факторов. Случайная составляющая и ее влияние на временной ряд могут быть оценены только с помощью статистических методов. Случайная составляющая проявляется как результат воздействия набора случайных факторов на исследуемый процесс и обычно выражается в повышенной изменчивости временного ряда, а также в отклонении значений детерминированной составляющей. Результирующее значение временного ряда это результат взаимодействия детерминированной и случайной составляющих. Простейший вид такого взаимодействия случай, когда, каждое значение временного ряда можно рассматривать как сумму (разность) двух значений, одно из которых обусловлено детерминированной составляющей, а другое случайной, т.е. x i =d i +p i. Модели временных рядов Наблюдаемые значения временного ряда представляют собой результат взаимодействия детерминированной и случайной составляющих. Различают два вида такого взаимодействия: Аддитивное значения временного ряда получаются как результат сложения детерминированной и случайной составляющих Мультипликативное значения временного ряда получаются как результат умножения детерминированной и случайной составляющих Соответственно, аддитивная модель имеет вид x i =d i +p i, мультипликативная модель имеет вид x i =d i p i. Компоненты временного ряда Типовые структуры, которые можно выделить во временном ряду тренд, сезонная компонента, циклическая компонента. Тогда детерминированная составляющая может быть записана в виде: d i =t i +s i +c i, где t i тренд, s i сезонная компонента, c i циклическая компонента.
3 Тренд Тренд медленно меняющаяся компонента временного ряд, которая описывает влияние на временной ряд долговременно действующих факторов, вызывающих плавные и длительные изменения ряда. Чтобы представить характер тренда, обычно достаточно взглянуть на график временного ряда. Наиболее популярные модели для описания тренда: Простая линейная модель: t i =a+b i Полиномиальная модель: t i =a+b 1 i+ b 2 i b n i n. В большинстве реальных задач степень полинома не превышает 5 Экспоненциальная модель: t i =exp(a+b i). Используется в случаях, когда процесс характеризуется равномерным увеличением темпов роста Логистическая модель t i =a./(1+b e - k i), где k константа, управляющая крутизной логистической функции. Такого типа кривые, имеющие S-образную форму, часто называют сигмоидами. Они хорошо описывают процессы с непостоянными темпами роста. Сезонная компонента Многим процессам свойственна повторяемость во времени, причем периодичность таких повторений может изменяться в очень широком диапазоне. Очевидно, что для описания таких периодических изменений, присутствующих во временных рядах, тренд непригоден. Сезонная компонента составляющая временного ряда, описывающая регулярные изменения его значений в пределах некоторого периода и представляющая сосбой последовательность почти повторяющихся циклов. Сезонная компонента может быть привязана к определенному календарному временному интервалу: дню, неделе, месяцу либо к какому-либо событию, которое пямо не соотносится с конкретными календарными интервалами. Сезонную компоненту с изменяющимся периодом иногда называют плавающей. Циклическая компонента Часто временные ряды содержат изменения, слишком плавные и заметные для случайной составляющей. В то же время такие изменения нельзя отнести ни к тренду, поскольку они не являются достаточно протяженными, ни к сезонной компоненте, поскольку они не являются регулярными. Подобные изменения называются циклической компонентой временного ряда. Циклическая компонента временного ряда интервалы подъема или спада, которые имеют различную протяженность, а также различную амплитуду расположенных в них значений. Изучение циклической компоненты часто оказывается полезным для прогнозирования, особенно краткосрочного.
4 Т.о., временной ряд можно представить как композицию, состоящую из двух составляющих случайной и детерминированной. Детерминированная составляющая, в свою очередь, содержит три компоненты тренд, сезонную и циклическую. Исследование временных рядов и автокорреляция Цель анализа временного ряда построение его математической модели, с помощью которой можно обнаружить закономерности поведения ряда, а также построить прогноз его дальнейшего развития. Временной ряд называется стационарным, если его статистические свойства (мат.ожидание и дисперсия) одинаковы на всем протяжении ряда. В противном случае ряд называется нестационарным. Прежде чем приступить к построению модели ряда, его стараются привести к стационарному. При исследовании временного ряда ищут ответы на несколько вопросов. Является ли ряд случайным? Содержит ля временной ряд тренд и сезонную компоненту? Является ли временной ряд стационарным? Для ответа используется аппарат корреляционного анализа. Корреляция характеризует степень статистической взаимосвязи между элементами данных. Если взаимосвязь между элементами присутствует, то данные называются коррелированными. Когда определяется степень статистической взаимосвязи между значениями одного временного ряда, имеет место автокорреляция. В этом случае вычисляется корреляция между временным рядом и его копией, сдвинутой на один или несколько временных отсчетов. Смысл корреляционного анализа заключается в следующем. Детерминированная составляющая характеризуется плавными изменениями значений ряда, т.е. соседние значения ряда не должны сильно отличаться, и, следовательно, между ними присутствует сильная зависимость. Если значения ряда в большей степени обусловлены случайной составляющей и соседние значения могут существенно отличаться друг от друга, то корреляция будет меньше. Пример. Пусть дан ряд, который содержит последовательность ежемесячных наблюдений за продажами. Месяц Продажи Январь 125 Февраль 130 Март 140 Апрель 132 Май 145 Июнь 150 Июль 148 Август 155 Сентябрь 157 Октябрь 160 Ноябрь 158 Декабрь 165
5 Для того, чтобы вычислить автокорреляцию ряда, будем использовать его копию, сдвинутую в сторону запаздывания на определенное количество отсчетов. X X i X i X i-n 125 Для определения степени взаимной зависимости элементов ряда используется коэффициент автокорреляции r k, где k количество отсчетов, на которое был сдвинут временной ряд при вычислении данного коэффициента. r k = n i= k+ 1 (x i x)(x (n k) σ i k 2 x x) где x i значение i-го отсчета, x i-k наблюдение x i со сдвигом на k временных отсчетов, x - - среднее значение ряда, σ -- дисперсия ряда. 2 x Коэффициент корреляции изменяется в диапазоне [-1,1], где r k =1 указывает на полную корреляцию Если рассчитать коэффициенты корреляции для каждого сдвига, получим последовательность коэффициентов, называемую автокорреляционной функцией (АКФ). Результаты расчета АКФ для ряда X. k r k Автокорреляционная функция временного ряда Значение коэффициента автокорреляции при нулевом сдвиге равно 1, поскольку ряд полностью коррелирован с самим собой. Также наблюдается высокая степень корреляции r k >0.8 при сдвиге менее чем на 4 временных отсчета и умеренная при r k для 5-7 отсчетов. Затем корреляция быстро падает. Т.о., можно сделать вывод о высокой степени зависимости между соседними значениями данного временного ряда. Данный вывод подтверждается визуальным исследованием ряда: в нем присутствует небольшой линейный положительный тренд, отсутствует сезонная компонента, а достаточно высокая гладкость позволяет выдвинуть предположение о малой величине случайной


6 составляющей. Все это хорошо согласуется с выводами, сделанными на основе корреляционного анализа. Для произвольного временного ряда, корреляционный анализ позволяет придти к следующим заключениям: Если ряд содержит тренд, то коэффициент автокорреляции значителен для первых нескольких сдвигов ряда, а в дальнейшем убывает до нуля Если действие случайной компоненты велико, то коэффициенты автокорреляции для любого значения сдвига будут близки к нулю. Случайный ряд и его АКФ Если ряд содержит сезонную компоненту, то коэффициент автокорреляции будет большим для значений сдвига, равных периоду сезонной составляющей или кратных ему. Ряд с сезонной компонентой и его АКФ
7 Таким образом, корреляционный анализ позволяет выявить в ряду тренд и сезонную компоненту, а также определять, насколько поведение ряда обусловлено его случайной компонентой. Знание данных свойств временного ряда помогает строить более адекватные модели и выбирать методы прогнозирования Модели прогнозирования Главный инструмент прогнозирования в современной бизнес-аналитике прогностические модели. Обобщенная модель прогноза Набор входных переменных x i (i=1,n) исходные данные для прогноза. Набор выходных переменных y j (j=1,m) набор прогнозируемых величин, n>m. Когда решается задача прогнозирования временного ряда, описывающего динамику изменения некоторого бизнес-процесса, входные значения наблюдения за развитием процесса в прошлом, а выходные прогнозируемые значения процесса в будущем. При этом временные интервала прошлых наблюдений и временные интервалы, по которым требуется получить прогноз, должны соответствовать друг другу. «Наивная» модель прогнозирования Предполагает, что последний период прогнозируемого временного ряда лучше всего описывает будущее этого ряда. Простейшая модель y(t+1)=x(t), где x(t) последнее наблюдаемое значение, y(t+1) прогноз. Чтобы модель учитывала наличие возможных трендов, ее можно несколько усложнить, например преобразовав к виду y(t+1)=x(t)+ или y(t+1)=x(t). При необходимости учета сезонных колебаний модель модифицируется следующим образом: y(t+1)=x(t-s), где s показатель, учитывающий сезонные изменения прогнозируемого временного ряда. Экстраполяция Если значения функции f(x) известны в некотором интервале , то целью экстраполяции является определение наиболее вероятного значения в точке x n+1. Экстраполяция применима только в тех случаях, когда функция f(x), а соответственно и описываемый ей временной ряд, достаточно стабильна и не подвержена резким изменениям.
8 Наиболее популярный метод экстраполяции в настоящее время экспоненциальное сглаживание. Основной его принцип заключается в том, чтобы учесть в прогнозе все наблюдения, но с экспоненциально убывающими весами. Метод позволяет принять во внимание сезонные колебания ряда и предсказать поведение трендовой составляющей. Например, в случае ряда с «нулевым» трендом, можно выбрать следующую модель экспоненциального сглаживания y(t+1)= λ y(t)+(1-λ) x(t), \где x(t) последнее наблюдаемое значение, y(t) прогноз на момент времени t, y(t+1) прогноз на момент времени t+1. 0< λ<1 параметр сглаживания или параметр адаптации, характеризующий меру обесценивания наблюдения за единицу времени. Инструментом прогноза является модель, первоначальная оценка параметра λ производится по нескольким первым наблюдениям. На ее основе делается прогноз, который сравнивается с фактическими наблюдениями. Далее модель корректируется в соответствии с величиной ошибки прогноза и вновь используется для прогнозирования следующего уровня, вплоть до исчерпания всех наблюдений. Таким образом, она постоянно «впитывает» новую информацию, приспосабливается к ней, и к концу периода наблюдения отображает тенденцию, сложившуюся на текущий момент. Прогноз получается как экстраполяция последней тенденции. Прогнозирование методом среднего и скользящего среднего Наиболее простая модель этой группы обычное усреднение набора наблюдений прогнозируемого ряда y(t+1)=(x(t)+x(t-1)+x(t-2)+ +x(1))/t. При усреднении сглаживаются резкие изменения и выбросы данных, что делает результаты прогноза более устойчивыми к изменчивости ряда, но в целом эта модель прогноза так же примитивна как «наивная». В формуле прогноза на основе среднего предполагается, что ряд усредняется по всем наблюдениям, но старые значения временного ряда могли формироваться на основе иных закономерностей и утратить актуальность. Чтобы повысить точность прогноза, можно использовать «скользящее среднее» y(t+1)=(x(t)+x(t-1)+x(t-2)+ +x(t-t))/(t+1), т.е. модель «видит» прошлое на Т отсчетов времени и прогноз строится только на этих наблюдениях. Иногда метод скользящего среднего оказывается даже эффективнее чем методы, основанные на долговременных наблюдениях. Регрессионные модели Один из методов прогнозирования временных рядов определение факторов, которые влияют на каждое значение временного ряда. Для этого выделяется каждая компонента временного ряда, вычисляется ее вклад в общую
9 составляющую, а затем на его основе прогнозируются будущие значения временного ряда. Данный метод получил название декомпозиции временного ряда. Исходный временной ряд представляется как композиция тренда, сезонной и циклической компоненты. Для построения прогноза выполняется выделение этих компонент из ряда, т.е. разложение ряда по компонентам. Рассмотрим прогнозирование методом декомпозиции с помощью тренда. Если тренд линейный, что типично для многих реальных временных рядов, то он представляет собой прямую линию, описываемую уравнением y=a+b t, где y значение ряда, a и b коэффициенты, определяющие расположение и наклон линии тренда, t время. Если уравнение линии тренда известно, то с его помощью можно рассчитать значение тренда в любой момент времени y t+k =a+b(t +k), где t начало прогноза, k горизонт прогноза. При использовании сезонности для прогнозирования методом декомпозиции сначала из временного ряда убирается тренд и сглаживается возможная циклическая компонента. Тогда можно считать, что оставшиеся данные будут обусловлены в основном сезонными колебаниями. На основе этих данных вычисляются так называемые сезонные индексы, которые характеризуют изменения временного ряда во времени. Например, временной ряд содержит наблюдения по месяцам в течение года. Сезонный индекс, равный 1, будет установлен для месяца, ожидаемое значение в котором составляет 1/12 от общей суммы по месяцам. Если для некоторого месяца устанавливается индекс 1.2, то ожидаемое значение для этого месяца составляет 1/12+20%, а если 0.8 то 1/12-20% и т.д. Ясно, что сумма сезонных индексов за год должны равняться 12. Использовать сезонность для прогнозирования можно тогда, когда сезонные колебания имеют хорошую повторяемость.
ПРАКТИЧЕСКАЯ РАБОТА 2 ИСПОЛЬЗОВАНИЕ МЕТОДА СКОЛЬЗЯЩЕЙ СРЕДНЕЙ В ПРОГНОЗИРОВАНИИ Цель работы: научиться строить тренд временного ряда на основе метода скользящей средней. Содержание работы: 1. Суть метода
ЛЕКЦИЯ 7 ДИНАМИЧЕСКИЕ МОДЕЛИ ОЦЕНИВАНИЕ МОДЕЛЕЙ С РАСПРЕДЕЛЕННЫМИ ЛАГАМИ ВРЕМЕННЫЕ РЯДЫ (ОСНОВНЫЕ ОПРЕДЕЛЕНИЯ) Эконометрические модели, которые в качестве регрессоров включают лаговые переменные, относятся
Лекция 12. Введение в анализ временных рядов Виды временных рядов. Требования, предъявляемые к исходной информации Статистическое описание развития экономических процессов во времени осуществляется с помощью
РАЗДЕЛ. ВРЕМЕННЫЕ РЯДЫ. АНАЛИЗ И ПРОГНОЗ ЭКОНОМИЧЕСКИХ ПОКАЗАТЕЛЕЙ ПО ИХ ВРЕМЕННЫМ РЯДАМ... ВРЕМЕННОЙ РЯД (ОПРЕДЕЛЕНИЯ, ПРИМЕРЫ, ФОРМУЛИРОВКА ОСНОВНЫХ ЗАДАЧ... СТАЦИОНАРНЫЕ ВРЕМЕННЫЕ РЯДЫ И ИХ ОСНОВНЫЕ
ТЕМА 4. АВТОКОРРЕЛЯЦИЯ УРОВНЕЙ ВРЕМЕННОГО РЯДА И ВЫЯВЛЕНИЕ ЕГО СТРУКТУРЫ При наличии во временном ряде тенденции и циклических колебаний значения каждого последующего уровня ряда зависят от предыдущих.
1. Общий анализ временного ряда. 1.1. Проверка гипотезы о случайности временного ряда. График временного ряда изучаемого показателя «Среднедушевые денежные доходы» изображен на рис. «Доходы населения».
Методология Box Jenkins (BJ) или модели AR(I)MA. Модель авторегрессии AR(p). Модель скользящего среднего MA(q). Модель авторегрессии AR(p) Целью эконометрического моделирования часто является так называемое
Эконометрическое моделирование Лабораторная работа 8 Анализ временных рядов Оглавление Понятие и виды временных рядов... 3 Прогнозирование экономических показателей на основе экстраполяции тренда... 3
Методология Box Jenkins (BJ) или модели AR(I)MA. Модель авторегрессии AR(p). Модель авторегрессии MA(q). Целью эконометрического моделирования часто является так называемое ou-of-sample предсказание, т.е.
Тема 10. Ряды динамики и их применение в анализе социально-экономических явлений. Изменение социально-экономических явлений во времени изучается статистикой методом построения и анализа динамических рядов.
МВДубатовская Теория вероятностей и математическая статистика Лекция 4 Регрессионный анализ Функциональная статистическая и корреляционная зависимости Во многих прикладных (в том числе экономических) задачах
УДК 338.4 ПРОГНОЗИРОВАНИЕ ОБЪЕМОВ ПРОДАЖ В МОДЕЛИ УПРАВЛЕНИЯ ЗАПАСАМИ 8 Ю.С. Чуйкова, Б.А. Горлач Ключевые слова: товарные запасы, управление запасами, прогноз продаж, сезонность, тренд, сезонная волна,
АКАДЕМИЯ НАРОДНОГО ХОЗЯЙСТВА ПРИ ПРАВИТЕЛЬСТВЕ РФ Институт Бизнеса и Делового Администрирования Примеры использования дополнительных надстроек MS Excel Анализ модельных временных рядов с помощью надстройки
Абдиев Б.А. «Эконометрика» Предназначено для студентов специальности: Финансы, вечернее отделение (2 курс 4г.о.) Учебный год: 2015-2016 Текст вопроса 1 Парная регрессия у=а+вх+е представляет собой регрессию
55 3 РЕГРЕССИОННЫЙ АНАЛИЗ 3 Постановка задачи регрессионного анализа Экономические показатели функционирования предприятия (отрасли хозяйства) как правило представляются таблицами статистических данных:
ОСНОВЫ РЕГРЕССИОННОГО АНАЛИЗА ПОНЯТИЕ КОРРЕЛЯЦИОННОГО И РЕГРЕССИОННОГО АНАЛИЗА Для решения задач экономического анализа и прогнозирования очень часто используются статистические, отчетные или наблюдаемые
1. Тема: Предпосылки МНК, методы их проверки Предпосылками метода наименьших квадратов (МНК) являются следующие функциональная связь между зависимой и независимой переменными присутствие в эконометрической
ПЛАН-КОНСПЕКТ. ТЕМА 5. МАТЕМАТИКО-СТАТИСТИЧЕСКИЕ МЕТОДЫ ИЗУЧЕНИЯ СВЯЗЕЙ Вопросы: 1. Сущность математико-статистических методов изучения связей 2. Корреляционный анализ 3. Регрессионный анализ 4. Кластерный
46 Глава 9. Регрессионный анализ 9.. Задачи регрессионного анализа Во время статистических наблюдений как правило получают значения нескольких признаков. Для простоты будем рассматривать в дальнейшем двумерные
Порядок выполнения работы. На основе имеющихся данных о производстве продукции за N лет рассчитать следующие величины: темпы прироста производства, производительность труда, производительность капитала.
Динамика рождаемости по Чувашской республике Содержание Введение 1. Общая тенденция рождаемости населения Чувашской республики 2. Основная тенденция рождаемости 3. Динамика рождаемости городского и сельского
3, 01 Г. В. Жукова Ìàòåìàòè åñêèå ìåòîäû èíâåñòèöèîííîãî ïëàíèðîâàíèÿ Аннотация: в данной статье рассмотрены основные математические методы, позволяющие получить прогнозные оценки развития тех или иных
Литература 1. Ханк Д.Э., Уичерн Д.У., Райтс А.Дж. Бизнес-прогнозирование, 7-е издание М.: Изд. Дом «Вильямс», 2003 2. Дуброва Т.А. Статистические методы прогнозирования/м. : ЮНИТИ- ДАНА, 2003 3. Вуколов
План лекций 1 семестр 1. Введение. 1.1. Предмет, метод и задачи статистики; источники статистической информации. 1.2. Кратка история развития статистики. Структура статистических органов на современном
Ср. температура 0 0,97789784683 Ср. осадки 0 0,893300077 Ср.температура/Осадки- 0,005975564 Данные, приведенные в табл. 4 показывают, что наиболее сильные корреляционные связи наблюдаются для среднегодовых
1 (64), 2012/ 33 The offered and realized additive model of calculation of specific norm of consumption of scrap metal at arc electric steel-smelting furnaces has allowed to reduce considerably the error
РЯДЫ ДИНАМИКИ КЛАССИФИКАЦИЯ Ряд динамики (РД), хронологический ряд, динамический ряд, временной ряд это последовательность упорядоченных во времени числовых показателей, характеризующих уровень развития
Прогнозирование в Excel методом скользящего среднего доктор физ. мат. наук, профессор Гавриленко В.В. ассистент Парохненко Л.М. (Национальный транспортный университет) Теоретическая справка. При моделировании
Контрольные тесты по дисциплине «Эконометрика» Первая главная компонента A. Содержит максимальную долю изменчивости всей матрицы факторов. B. Отражает степень влияния первого фактора на результат. C. Отражает
Алеткин П.А., Кожемякова В.В., Шайдуллина Л.И. Прогнозирование доходов и расходов предприятия на основе мультипликативной модели временных рядов В данной практической статье авторами рассмотрено применение
6 целей инвестирования в ИТ (опрос) Повышение эффективности операционной деятельности Новые товары, услуги, бизнес-модели Тесные контакты с покупателями и поставщиками Поддержка принятия решений Конкурентные
Лекция 5. Элементы теории корреляции.. Функциональная, статистическая и корреляционная зависимости. Две случайные величины могут быть связаны функциональной зависимостью, т.е. изменение одной из них по
АВТОМАТИЗАЦИЯ ЭКОНОМЕТРИЧЕСКОГО МОДЕЛИРОВАНИЯ Т. А. Заяц УО «Белорусский торгово-экономический университет потребительской кооперации», г. Гомель В современных экономических условиях планирование и управление
УДК 519.862. Физико-математические науки Летова Марина Сергеевна, студентка Факультет прикладной математики и механики, Федеральное государственное бюджетное образовательное учреждение высшего профессионального
Автокорреляция в остатках. Критерий Дарбина-Уотсона. Бондар Е. В. Филиал Федерального государственного автономного образовательного учреждения высшего образования «Южный федеральный университет» в г. Новошахтинске
ЗАДАЧИ И МЕТОДЫ ПРОГНОЗИРОВАНИЯ В ГОРНОМ ДЕЛЕ Прогнозирование событий, и в частности, последствий разработки полезных ископаемых, чрезвычайно сложное дело из-за взаимосвязанности процессов в биосфере.
Лекция 8 Тема Сравнение случайных величин или признаков. Содержание темы Аналогия дискретных СВ и выборок Виды зависимостей двух случайных величин (выборок) Функциональная зависимость. Линии регрессии.
11. МЕТОДИЧЕСКИЕ УКАЗАНИЯ ДЛЯ ОБУЧАЮЩИХСЯ ПО ОСВОЕНИЮ ДИСЦИПЛИНЫ. Приступая к изучению дисциплины, студенту необходимо внимательно ознакомиться с тематическим планом занятий, списком рекомендованной литературы.
Алеткин П.А., Кожемякова В.В., Шайдуллина Л.И. Прогнозный анализ доходов и расходов от обычных видов деятельности с помощью построения аддитивной модели временного ряда В данной практической статье авторами
Линейная корреляционная зависимость Часто на практике требуется установить вид и оценить силу зависимости изучаемой случайной величины Y от одной или нескольких других величин (случайных или неслучайных).
Кафедра экономики и управления Статистика Учебно-методический комплекс для студентов ФСПО, обучающихся с применением дистанционных технологий Модуль 6 Ряды динамики Составитель: Ст. преподаватель Е.Н.
Иткин В.Ю. Модели ARMAX Семинар 4. Временные ряды. Автокорреляционная функция 4.1. Пример временного ряда Рассмотрим пример: серия измерений давления газа на выходе из абсорбера на УКПГ. На первый взгляд,
Лекция 5 ЭКОНОМЕТРИКА 5 Проверка качества уравнения регрессии Предпосылки метода наименьших квадратов Рассмотрим модель парной линейной регрессии X 5 Пусть на основе выборки из n наблюдений оценивается
Регрессионный анализ регрессионный анализ -введение коэффициент корреляции степень связи в вариации двух переменных величин (мера тесноты этой связи) метод регрессии позволяет судить как количественно
Тема 2.3. Построение линейно-регрессионной модели экономического процесса Пусть имеются две измеренные случайные величины (СВ) X и Y. В результате проведения n измерений получено n независимых пар. Перед
7 (35) 008 Рынок ценных бумаг Применение анализа временных рядов в стратегии инвестора и торговой системе трейдера Е.Е. Лещенко Кафедра менеджмента инвестиций и инноваций Российской экономической академии
Задачи для текущего контроля Задача 1 Администрация банка изучает динамику депозитов физических лиц за ряд лет (млн долл. в сопоставимых ценах). Исходные данные представлены ниже: Сумма Время, лет 1 2
3.4. СТАТИСТИЧЕСКИЕ ХАРАКТЕРИСТИКИ ВЫБОРОЧНЫХ ЗНАЧЕНИЙ ПРОГНОЗНЫХ МОДЕЛЕЙ До сих пор мы рассматривали способы построения прогнозных моделей стационарных процессов, не учитывая одной весьма важной особенности.
НАУЧНЫЙ ВЕСТНИК ИЭП им Гайдарару 5 ПРОГНОЗИРОВАНИЕ В ПЕРИОДЫ ЭКОНОМИЧЕСКОЙ НЕСТАБИЛЬНОСТИ: СУЩЕСТВУЮТ ЛИ ПРОСТЫЕ СПОСОБЫ УЛУЧШЕНИЯ КАЧЕСТВА ПРОГНОЗОВ МТурунцева зав лабораторией ИЭП им ЕТ Гайдара и РАНХиГС
Управление производством УДК 631.15:338.27 ПРОГНОСТИЧЕСКИЕ МЕТОДЫ В УПРАВЛЕНИИ ПРОИЗВОДСТВОМ ЗЕРНОВЫХ КУЛЬТУР Е. Г. НИКИТЕНКО, аспирант кафедры менеджмента Е-mail: [email protected] Ставропольский государственный
Новые возможности программы ФемтоСкан Советы и рекомендации Выпуск 003 Волшебство корреляционного анализа. Часть 1. В сканирующей зондовой микроскопии, и в первую очередь в сканирующей туннельной микроскопии,
36 УДК 68.3.068 А.Ю. СОКОЛОВ, О.С. РАДИВОНЕНКО, Т.В. КОРЧАК Национальный аэрокосмический университет им. Н. Е. Жуковского ХАИ, Украина МЕТОДЫ АНАЛИЗА ВРЕМЕННЫХ РЯДОВ В ЗАДАЧАХ ПРОГНОЗИРОВАНИЯ ВСПЫШЕК ЭПИДЕМИЙ
Эконометрическое моделирование Лабораторная работа 7 Анализ остатков. Автокорреляция Оглавление Свойства остатков... 3 1-е условие Гаусса-Маркова: Е(ε i) = 0 для всех наблюдений... 3 2-е условие Гаусса-Маркова:
Трансформация упорядоченных данных Многие аналитические задачи, например прогнозирование, анализ продаж, динамики спроса, состояния бизнес-объектов и других протяженных во времени процессов, связаны
Эконометрическое моделирование Лабораторная работа Корреляционный анализ Оглавление Понятие корреляционного и регрессионного анализа... 3 Парный корреляционный анализ. Коэффициент корреляции... 4 Задание
ЛЕКЦИЯ Сообщения, сигналы, помехи как случайные явления Случайные величины, вектора и процессы 4 СИГНАЛЫ И ПОМЕХИ В РТС КАК СЛУЧАЙНЫЕ ЯВЛЕНИЯ Как уже отмечалось выше основная проблематика теории РТС это
УДК 674.093 ЭВОЛЮЦИЯ ТРЕНДА И ВНУТРИГОДОВОЙ ДИНАМИКИ КИСЛОТНОСТИ ОСАДКОВ, ВЫПАДАЮЩИХ В ТВЕРИ Ф. В. Качановский В предыдущих публикациях автора рассмотрены различные аспекты проблемы кислотности атмосферных
"УТВЕРЖДАЮ" Заместитель Председателя Правления ОАО "СО ЦДУ ЕЭС" Н.Г. Шульгинов 4 декабря 2007 г. Методика прогнозирования графиков электропотребления для технологий краткосрочного планирования 2007 Содержание.
Корреляционный анализ. Корреляционно-регрессионный анализ выполняется на основе анализа эмпирических данных. Методы такого анализа являются составной частью эконометрики, которая устанавливает и исследует
ЛАБОРАТОРНАЯ РАБОТА N o.1 СЛОЖЕНИЕ ОДНОНАПРАВЛЕННЫХ И ВЗАИМНО ПЕРПЕНДИКУЛЯРНЫХ КОЛЕБАНИЙ Цель работы Целью работы является практическое ознакомление с физикой гармонических колебаний, исследование процесса
Лекция. Основные показатели динамики экономических явлений На практике для количественной оценки динамики явлений широко применяются следующие основные аналитические показатели: абсолютные приросты; темпы
УДК 330.42 Экономические науки Харитонова Дарья Евгеньевна, студентка кафедры прикладной математики, специальность «Математическое и информационное обеспечение экономической деятельности», ФГБОУ ВО «Пермский
В трех предыдущих заметках описаны регрессионные модели, позволяющие прогнозировать отклик по значениям объясняющих переменных. В настоящей заметке мы покажем, как с помощью этих моделей и других статистических методов анализировать данные, собранные на протяжении последовательных временных интервалов. В соответствии с особенностями каждой компании, упомянутой в сценарии, мы рассмотрим три альтернативных подхода к анализу временных рядов.
Материал будет проиллюстрирован сквозным примером: прогнозирование доходов трех компаний . Представьте себе, что вы работаете аналитиком в крупной финансовой компании. Чтобы оценить инвестиционные перспективы своих клиентов, вам необходимо предсказать доходы трех компаний. Для этого вы собрали данные о трех интересующих вас компаниях - Eastman Kodak, Cabot Corporation и Wal-Mart. Поскольку компании различаются по виду деловой активности, каждый временной ряд обладает своими уникальными особенностями. Следовательно, для прогнозирования необходимо применять разные модели. Как выбрать наилучшую модель прогнозирования для каждой компании? Как оценить инвестиционные перспективы на основе результатов прогнозирования?
Обсуждение начинается с анализа ежегодных данных. Демонстрируются два метода сглаживания таких данных: скользящее среднее и экспоненциальное сглаживание. Затем демонстрируется процедура вычисления тренда с помощью метода наименьших квадратов и более сложные методы прогнозирования. В заключение, эти модели распространяются на временные ряды, построенные на основе ежемесячных или ежеквартальных данных.
Скачать заметку в формате или , примеры в формате
Прогнозирование в бизнесе
Поскольку экономические условия с течением времени изменяются, менеджеры должны прогнозировать влияние, которое эти изменения окажут на их компанию. Одним из методов, позволяющих обеспечить точное планирование, является прогнозирование. Несмотря на большое количество разработанных методов, все они преследуют одну и ту же цель - предсказать события, которые произойдут в будущем, чтобы учесть их при разработке планов и стратегии развития компании.
Современное общество постоянно испытывает необходимость в прогнозировании. Например, чтобы выработать правильную политику, члены правительства должны прогнозировать уровни безработицы, инфляции, промышленного производства, подоходного налога отдельных лиц и корпораций. Чтобы определить потребности в оборудовании и персонале, директора авиакомпаний должны правильно предсказать объем авиаперевозок. Для того чтобы создать достаточное количество мест в общежитии, администраторы колледжей или университетов хотят знать, сколько студентов поступят в их учебное заведение в следующем году.
Существуют два общепринятых подхода к прогнозированию: качественный и количественный. Методы качественного прогнозирования особенно важны, если исследователю недоступны количественные данные. Как правило, эти методы носят весьма субъективный характер. Если статистику доступны данные об истории объекта исследования, следует применять методы количественного прогнозирования. Эти методы позволяют предсказать состояние объекта в будущем на основе данных о его прошлом. Методы количественного прогнозирования разделяются на две категории: анализ временных рядов и методы анализа причинно-следственных зависимостей.
Временной ряд - это набор числовых данных, полученных в течение последовательных периодов времени. Метод анализа временных рядов позволяет предсказать значение числовой переменной на основе ее прошлых и настоящих значений. Например, ежедневные котировки акций на Нью-Йоркской фондовой бирже образуют временной ряд. Другим примером временного ряда являются ежемесячные значения индекса потребительских цен, ежеквартальные величины валового внутреннего продукта и ежегодные доходы от продаж какой-нибудь компании.
Методы анализа причинно-следственных зависимостей позволяют определить, какие факторы влияют на значения прогнозируемой переменной. К ним относятся методы множественного регрессионного анализа с запаздывающими переменными, эконометрическое моделирование, анализ лидирующих индикаторов, методы анализа диффузионных индексов и других экономических показателей. Мы расскажем лишь о методах прогнозирования на основе анализа временны х рядов.
Компоненты классической мультипликативной модели временны х рядов
Основное предположение, лежащее в основе анализа временных рядов, состоит в следующем: факторы, влияющие на исследуемый объект в настоящем и прошлом, будут влиять на него и в будущем. Таким образом, основные цели анализа временных рядов заключаются в идентификации и выделении факторов, имеющих значение для прогнозирования. Чтобы достичь этой цели, были разработаны многие математические модели, предназначенные для исследования колебаний компонентов, входящих в модель временного ряда. Вероятно, наиболее распространенной является классическая мультипликативная модель для ежегодных, ежеквартальных и ежемесячных данных. Для демонстрации классической мультипликативной модели временных рядов рассмотрим данные о фактических доходах компании Wm.Wrigley Jr. Company за период с 1982 по 2001 годы (рис. 1).
Рис. 1. График фактического валового дохода компании Wm.Wrigley Jr. Company (млн. долл. в текущих ценах) за период с 1982 по 2001 годы
Как видим, на протяжении 20 лет фактический валовой доход компании имел возрастающую тенденцию. Эта долговременная тенденция называется трендом. Тренд - не единственный компонент временного ряда. Кроме него, данные имеют циклический и нерегулярный компоненты. Циклический компонент описывает колебание данных вверх и вниз, часто коррелируя с циклами деловой активности. Его длина изменяется в интервале от 2 до 10 лет. Интенсивность, или амплитуда, циклического компонента также не постоянна. В некоторые годы данные могут быть выше значения, предсказанного трендом (т.е. находиться в окрестности пика цикла), а в другие годы - ниже (т.е. быть на дне цикла). Любые наблюдаемые данные, не лежащие на кривой тренда и не подчиняющиеся циклической зависимости, называются иррегулярными или случайными компонентами . Если данные записываются ежедневно или ежеквартально, возникает дополнительный компонент, называемый сезонным . Все компоненты временных рядов, характерных для экономических приложений, приведены на рис. 2.

Рис. 2. Факторы, влияющие на временные ряды
Классическая мультипликативная модель временного ряда утверждает, что любое наблюдаемое значение является произведением перечисленных компонентов. Если данные являются ежегодными, наблюдение Y i , соответствующее i -му году, выражается уравнением:
(1) Y i = T i * C i * I i
где T i - значение тренда, C i i -ом году, I i i -ом году.
Если данные измеряются ежемесячно или ежеквартально, наблюдение Y i , соответствующее i-му периоду, выражается уравнением:
(2) Y i = T i *S i *C i *I i
где T i - значение тренда, S i - значение сезонного компонента в i -ом периоде, C i - значение циклического компонента в i -ом периоде, I i - значение случайного компонента в i -ом периоде.
На первом этапе анализа временных рядов строится график данных и выявляется их зависимость от времени. Сначала необходимо выяснить, существует ли долговременное возрастание или убывание данных (т.е. тренд), или временной ряд колеблется вокруг горизонтальной линии. Если тренд отсутствует, то для сглаживания данных можно применить метод скользящих средних или экспоненциального сглаживания.
Сглаживание годовых временных рядов
В сценарии мы упомянули о компании Cabot Corporation. Имея штаб-квартиру в Бостоне, штат Массачусеттс, она специализируется на производстве и продаже химикатов, строительных материалов, продуктов тонкой химии, полупроводников и сжиженного природного газа. Компания имеет 39 заводов в 23 странах. Рыночная стоимость компании составляет около 1,87 млрд. долл. Ее акции котируются на Нью-Йоркской фондовой бирже под аббревиатурой СВТ. Доходы компании за указанный период приведены на рис. 3.

Рис. 3. Доходы компании Cabot Corporation в 1982–2001 годах (млрд. долл.)
Как видим, долговременная тенденция повышения доходов затемнена большим количеством колебаний. Таким образом, визуальный анализ графика не позволяет утверждать, что данные имеют тренд. В таких ситуациях можно применить методы скользящего среднего или экспоненциального сглаживания.
Скользящие средние. Метод скользящих средних весьма субъективен и зависит от длины периода L , выбранного для вычисления средних значений. Для того чтобы исключить циклические колебания, длина периода должна быть целым числом, кратным средней длине цикла. Скользящие средние для выбранного периода, имеющего длину L , образуют последовательность средних значений, вычисленных для последовательностей длины L . Скользящие средние обозначаются символами MA(L) .
Предположим, что мы хотим вычислить пятилетние скользящие средние значения по данным, измеренным в течение n = 11 лет. Поскольку L = 5, пятилетние скользящие средние образуют последовательность средних значений, вычисленных по пяти последовательным значениям временного ряда. Первое из пятилетних скользящих средних значений вычисляется путем суммирования данных о первых пяти годах с последующим делением на пять:
![]()
Второе пятилетнее скользящее среднее вычисляется путем суммирования данных о годах со 2-го по 6-й с последующим делением на пять:
![]()
Этот процесс продолжается, пока не будет вычислено скользящее среднее для последних пяти лет. Работая с годовыми данными, следует полагать число L (длину периода, выбранного для вычисления скользящих средних) нечетным. В этом случае невозможно вычислить скользящие средние для первых (L – 1)/2 и последних (L – 1)/2 лет. Следовательно, при работе с пятилетними скользящими средними невозможно выполнить вычисления для первых двух и последних двух лет. Год, для которого вычисляется скользящее среднее, должен находиться в середине периода, имеющего длину L . Если n = 11, a L = 5, первое скользящее среднее должно соответствовать третьему году, второе - четвертому, а последнее - девятому. На рис. 4 показаны графики 3- и 7-летних скользящих средних, вычисленные для доходов компании Cabot Corporation за период с 1982 по 2001 годы.

Рис. 4. Графики 3- и 7-летних скользящих средних, вычисленные для доходов компании Cabot Corporation
Обратите внимание на то, что при вычислении трехлетних скользящих средних проигнорированы наблюдаемые значения, соответствующие первому и последнему годам. Аналогично при вычислении семилетних скользящих средних нет результатов для первых и последних трех лет. Кроме того, семилетние скользящие средние намного больше сглаживают временной ряд, чем трехлетние. Это происходит потому, что семилетним скользящим средним соответствует более долгий период. К сожалению, чем больше длина периода, тем меньшее количество скользящих средних можно вычислить и представить на графике. Следовательно, больше семи лет для вычисления скользящих средних выбирать нежелательно, поскольку из начала и конца графика выпадет слишком много точек, что исказит форму временного ряда.
Экспоненциальное сглаживание. Для выявления долговременных тенденций, характеризующих изменения данных, кроме скользящих средних, применяется метод экспоненциального сглаживания. Этот метод позволяет также делать краткосрочные прогнозы (в рамках одного периода), когда наличие долговременных тенденций остается под вопросом. Благодаря этому метод экспоненциального сглаживания обладает значительным преимуществом над методом скользящих средних.
Метод экспоненциального сглаживания получил свое название от последовательности экспоненциально взвешенных скользящих средних. Каждое значение в этой последовательности зависит от всех предыдущих наблюдаемых значений. Еще одно преимущество метода экспоненциального сглаживания над методом скользящего среднего заключается в том, что при использовании последнего некоторые значения отбрасываются. При экспоненциальном сглаживании веса, присвоенные наблюдаемым значениям, убывают со временем, поэтому после выполнения вычислений наиболее часто встречающиеся значения получат наибольший вес, а редкие величины - наименьший. Несмотря на громадное количество вычислений, Excel позволяет реализовать метод экспоненциального сглаживания.
Уравнение, позволяющее сгладить временной ряд в пределах произвольного периода времени i , содержит три члена: текущее наблюдаемое значение Y i , принадлежащее временному ряду, предыдущее экспоненциально сглаженное значение E i –1 и присвоенный вес W .
(3) E 1 = Y 1 E i = WY i + (1 – W)E i–1 , i = 2, 3, 4, …
где E i – значение экспоненциально сглаженного ряда, вычисленное для i -го периода, E i –1 – значение экспоненциально сглаженного ряда, вычисленное для (i – 1)-гo периода, Y i – наблюдаемое значение временного ряда в i -ом периоде, W – субъективный вес, или сглаживающий коэффициент (0 < W < 1).
Выбор сглаживающего коэффициента, или веса, присвоенного членам ряда, является принципиально важным, поскольку он непосредственно влияет на результат. К сожалению, этот выбор до некоторой степени субъективен. Если исследователь хочет просто исключить из временного ряда нежелательные циклические или случайные колебания, следует выбирать небольшие величины W (близкие к нулю). С другой стороны, если временной ряд используется для прогнозирования, необходимо выбрать большой вес W (близкий к единице). В первом случае четко проявляются долговременные тенденции временного ряда. Во втором случае повышается точность краткосрочного прогнозирования (рис. 5).

Рис. 5 Графики экспоненциально сглаженного временного ряда (W=0,50 и W=0,25) для данных о доходах компании Cabot Corporation за период с 1982 по 2001 годы; формулы расчета см. в файле Excel
Экспоненциально сглаженное значение, полученное для i -го временного интервала, можно использовать в качестве оценки предсказанного значения в (i +1)-м интервале:
![]()
Для предсказания доходов компании Cabot Corporation в 2002 году на основе экспоненциально сглаженного временного ряда, соответствующего весу W = 0,25, можно использовать сглаженное значение, вычисленное для 2001 года. Из рис. 5 видно, что эта величина равна 1651,0 млн. долл. Когда станут доступными данные о доходах компании в 2002 году, можно применить уравнение (3) и предсказать уровень доходов в 2003 году, используя сглаженное значение доходов в 2002 году:
Пакет анализа Excel способен построить график экспоненциального сглаживания в один клик. Пройдите по меню Данные → Анализ данных и выберите опцию Экспоненциальное сглаживание (рис. 6). В открывшемся окне Экспоненциальное сглаживание задайте параметры. К сожалению, процедура позволяет построить только один сглаженный ряд, поэтому, если вы хотите «поиграть» с параметром W , повторите процедуру.

Рис. 6. Построение графика экспоненциального сглаживания с помощью Пакета анализа
Вычисление трендов с помощью метода наименьших квадратов и прогнозирование
Среди компонентов временного ряда чаще других исследуется тренд. Именно тренд позволяет делать краткосрочные и долгосрочные прогнозы. Для выявления долговременной тенденции изменения временного ряда обычно строят график, на котором наблюдаемые данные (значения зависимой переменной) откладываются на вертикальной оси, а временные интервалы (значения независимой переменной) - на горизонтальной. В этом разделе мы опишем процедуру выявления линейного, квадратичного и экспоненциального тренда с помощью метода наименьших квадратов.
Модель линейного тренда является простейшей моделью, применяемой для прогнозирования: Y i = β 0 + β 1 X i + ε i . Уравнение линейного тренда:
![]()
При заданном уровне значимости α нулевая гипотеза отклоняется, если тестовая t -статистика больше верхнего или меньше нижнего критического уровня t -распределения. Иначе говоря, решающее правило формулируется следующим образом: если t > t U или t < t L , нулевая гипотеза Н 0 отклоняется, в противном случае нулевая гипотеза не отклоняется (рис. 14).

Рис. 14. Области отклонения гипотезы для двустороннего критерия значимости параметра авторегрессии А р , имеющего наивысший порядок
Если нулевая гипотеза (А р = 0) не отклоняется, значит, выбранная модель содержит слишком много параметров. Критерий позволяет отбросить старший член модели и оценить авторегрессионную модель порядка р–1 . Эту процедуру следует продолжать до тех пор, пока нулевая гипотеза Н 0 не будет отклонена.
- Выберите порядок р оцениваемой авторегрессионной модели с учетом того, что t -критерий значимости имеет n –2р–1 степеней свободы.
- Сформируйте последовательность переменных р «с запаздыванием» так, чтобы первая переменная запаздывала на один временной интервал, вторая - на два и так далее. Последнее значение должно запаздывать на р временных интервалов (см. рис. 15).
- Примените Пакет анализа Excel для вычисления регрессионной модели, содержащей все р значений временного ряда с запаздыванием.
- Оцените значимость параметра А Р , имеющего наивысший порядок: а) если нулевая гипотеза отклоняется, в авторегрессионную модель можно включать все р параметров; б) если нулевая гипотеза не отклоняется, отбросьте р -ю переменную и повторите п.3 и 4 для новой модели, включающей р–1 параметр. Проверка значимости новой модели основана на t -критерии, количество степеней свободы определяется новым количеством параметров.
- Повторяйте п.3 и 4, пока старший член авторегрессионной модели не станет статистически значимым.
Чтобы продемонстрировать авторегрессионное моделирование, вернемся к анализу временного ряда реальных доходов компании Wm. Wrigley Jr. На рис. 15 показаны данные, необходимые для построения авторегрессионных моделей первого, второго и третьего порядка. Для построения модели третьего порядка необходимы все столбцы этой таблицы. При построении авторегрессионной модели второго порядка последний столбец игнорируется. При построении авторегрессионной модели первого порядка игнорируются два последних столбца. Таким образом, при построении авторегрессионных моделей первого, второго и третьего порядка из 20 переменных исключаются одна, две и три соответственно.

Выбор наиболее точной авторегрессионной модели начинается с модели третьего порядка. Для корректной работы Пакета анализа следует в качестве входного интервала Y указать диапазон В5:В21, а входного интервала для Х – С5:Е21. Данные анализа приведены на рис. 16.

Проверим значимость параметра А 3 , имеющего наивысший порядок. Его оценка а 3 равна –0,006 (ячейка С20 на рис. 16), а стандартная ошибка равна 0,326 (ячейка D20). Для проверки гипотез Н 0: А 3 = 0 и Н 1: А 3 ≠ 0 вычислим t -статистику:

t -критерия с n–2p–1 = 20–2*3–1 = 13 степенями свободы равны: t L =СТЬЮДЕНТ.ОБР(0,025;13) = –2,160; t U =СТЬЮДЕНТ.ОБР(0,975;13) = +2,160. Поскольку –2,160 < t = –0,019 < +2,160 и р = 0,985 > α = 0,05, нулевую гипотезу Н 0 отклонять нельзя. Таким образом, параметр третьего порядка не имеет статистической значимости в авторегрессионной модели и должен быть удален.
Повторим анализ для авторегрессионной модели второго порядка (рис. 17). Оценка параметра, имеющего наивысший порядок, а 2 = –0,205, а ее стандартная ошибка равна 0,276. Для проверки гипотез Н 0: А 2 = 0 и Н 1: А 2 ≠ 0 вычислим t -статистику:


При уровне значимости α = 0,05, критические величины двухстороннего t -критерия с n–2p–1 = 20–2*2–1 = 15 степенями свободы равны: t L =СТЬЮДЕНТ.ОБР(0,025;15) = –2,131; t U =СТЬЮДЕНТ.ОБР(0,975;15) = +2,131. Поскольку –2,131 < t = –0,744 < –2,131 и р = 0,469 > α = 0,05, нулевую гипотезу Н 0 отклонять нельзя. Таким образом, параметр второго порядка не является статистически значимым, и его следует удалить из модели.
Повторим анализ для авторегрессионной модели первого порядка (рис. 18). Оценка параметра, имеющего наивысший порядок, а 1 = 1,024, а ее стандартная ошибка равна 0,039. Для проверки гипотез Н 0: А 1 = 0 и Н 1: А 1 ≠ 0 вычислим t -статистику:


При уровне значимости α = 0,05, критические величины двухстороннего t -критерия с n–2p–1 = 20–2*1–1 = 17 степенями свободы равны: t L =СТЬЮДЕНТ.ОБР(0,025;17) = –2,110; t U =СТЬЮДЕНТ.ОБР(0,975;17) = +2,110. Поскольку –2,110 < t = 26,393 < –2,110 и р = 0,000 < α = 0,05, нулевую гипотезу Н 0 следует отклонить. Таким образом, параметр первого порядка является статистически значимым, и его нельзя удалять из модели. Итак, модель авторегрессии первого порядка лучше других аппроксимирует исходные данные. Используя оценки а 0 = 18,261, а 1 = 1,024 и значение временного ряда за последний год - Y 20 = 1 371,88, можно предсказать величину реальных доходов компании Wm. Wrigley Jr. Company в 2002 г.:
Выбор адекватной модели прогнозирования
Выше были описаны шесть методов прогнозирования значений временного ряда: модели линейного, квадратичного и экспоненциального трендов и авторегрессионные модели первого, второго и третьего порядков. Существует ли оптимальная модель? Какую из шести описанных моделей следует применять для прогнозирования значения временного ряда? Ниже перечислены четыре принципа, которыми необходимо руководствоваться при выборе адекватной модели прогнозирования. Эти принципы основаны на оценках точности моделей. При этом предполагается, что значения временного ряда можно предсказать, изучая его предыдущие значения.
Принципы выбора моделей для прогнозирования:
- Выполните анализ остатков.
- Оцените величину остаточной ошибки с помощью квадратов разностей.
- Оцените величину остаточной ошибки с помощью абсолютных разностей.
- Руководствуйтесь принципом экономии.
Анализ остатков. Напомним, что остатком называется разность между предсказанным и наблюдаемым значением. Построив модель для временного ряда, следует вычислить остатки для каждого из n интервалов. Как показано на рис. 19, панель А, если модель является адекватной, остатки представляют собой случайный компонент временного ряда и, следовательно, распределены нерегулярно. С другой стороны, как показано на остальных панелях, если модель не адекватна, остатки могут иметь систематическую зависимость, не учитывающую либо тренд (панель Б), либо циклический (панель В), либо сезонный компонент (панель Г).

Рис. 19. Анализ остатков
Измерение абсолютной и среднеквадратичной остаточных погрешностей. Если анализ остатков не позволяет определить единственную адекватную модель, можно воспользоваться другими методами, основанными на оценке величины остаточной погрешности. К сожалению, статистики не пришли к консенсусу относительно наилучшей оценки остаточных погрешностей моделей, применяемых для прогнозирования. Исходя из принципа наименьших квадратов, можно сначала провести регрессионный анализ и вычислить стандартную ошибку оценки S XY . При анализе конкретной модели эта величина представляет собой сумму квадратов разностей между фактическим и предсказанным значениями временного ряда. Если модель идеально аппроксимирует значения временного ряда в предыдущие моменты времени, стандартная ошибка оценки равна нулю. С другой стороны, если модель плохо аппроксимирует значения временного ряда в предыдущие моменты времени, стандартная ошибка оценки велика. Таким образом, анализируя адекватность нескольких моделей, можно выбрать модель, имеющую минимальную стандартную ошибку оценки S XY .
Основным недостатком такого подхода является преувеличение ошибок при прогнозировании отдельных значений. Иначе говоря, любая большая разность между величинами Y i и Ŷ i при вычислении суммы квадратов ошибок SSE возводится в квадрат, т.е. увеличивается. По этой причине многие статистики предпочитают применять для оценки адекватности модели прогнозирования среднее абсолютное отклонение (mean absolute deviation - MAD):

При анализе конкретных моделей величина MAD представляет собой среднее значение модулей разностей между фактическим и предсказанными значениями временного ряда. Если модель идеально аппроксимирует значения временного ряда в предыдущие моменты времени, среднее абсолютное отклонение равно нулю. С другой стороны, если модель плохо аппроксимирует такие значения временного ряда, среднее абсолютное отклонение велико. Таким образом, анализируя адекватность нескольких моделей, можно выбрать модель, имеющую минимальное среднее абсолютное отклонение.
Принцип экономии. Если анализ стандартных ошибок оценок и средних абсолютных отклонений не позволяет определить оптимальную модель, можно воспользоваться четвертым методом, основанным на принципе экономии. Этот принцип утверждает, что из нескольких равноправных моделей следует выбирать простейшую.
Среди шести рассмотренных в главе моделей прогнозирования наиболее простыми являются линейная и квадратичная регрессионные модели, а также авторегрессионная модель первого порядка. Остальные модели намного сложнее.
Сравнение четырех методов прогнозирования. Для иллюстрации процесса выбора оптимальной модели вернемся к временному ряду, состоящему из величин реального дохода компании Wm. Wrigley Jr. Company. Сравним четыре модели: линейную, квадратичную, экспоненциальную и авторегрессионную модель первого порядка. (Авторегрессионные модели второго и третьего порядка лишь незначительно улучшают точность прогнозирования значений данного временного ряда, поэтому их можно не рассматривать.) На рис. 20 показаны графики остатков, построенные при анализе четырех методов прогнозирования с помощью Пакета анализа Excel. Делая выводы на основе этих графиков, следует быть осторожным, поскольку временной ряд содержит только 20 точек. Методы построения см. соответствующий лист Excel-файла.

Рис. 20. Графики остатков, построенные при анализе четырех методов прогнозирования с помощью Пакета анализа Excel
Ни одна модель, кроме авторегрессионой модели первого порядка, не учитывает циклический компонент. Именно эта модель лучше других аппроксимирует наблюдения и характеризуется наименее систематической структурой. Итак, анализ остатков всех четырех методов показал, что наилучшей является авторегрессионная модель первого порядка, а линейная, квадратичная и экспоненциальная модели имеют меньшую точность. Чтобы убедиться в этом, сравним величины остаточных погрешностей этих методов (рис. 21). С методикой расчетов можно ознакомиться, открыв Excel-файл. На рис. 21 указаны фактические значения Y i (колонка Реальный доход ), предсказанные значения Ŷ i , а также остатки е i для каждой из четырех моделей. Кроме того, показаны значения S YX и MAD . Для всех четырех моделей величинs S YX и MAD примерно одинаковые. Экспоненциальная модель является относительно худшей, а линейная и квадратичная модели превосходят ее по точности. Как и ожидалось, наименьшие величины S YX и MAD имеет авторегрессионная модель первого порядка.

Рис. 21. Сравнение четырех методов прогнозирования с помощью показателей S YX и MAD
Выбрав конкретную модель прогнозирования, необходимо внимательно следить за дальнейшими изменениями временного ряда. Помимо всего прочего, такая модель создается, чтобы правильно предсказывать значения временного ряда в будущем. К сожалению, такие модели прогнозирования плохо учитывают изменения в структуре временного ряда. Совершенно необходимо сравнивать не только остаточную погрешность, но и точность прогнозирования будущих значений временного ряда, полученную с помощью других моделей. Измерив новую величину Y i в наблюдаемом интервале времени, ее необходимо тотчас же сравнить с предсказанным значением. Если разница слишком велика, модель прогнозирования следует пересмотреть.
Прогнозирование временны х рядов на основе сезонных данных
До сих пор мы изучали временные ряды, состоящие из годовых данных. Однако многие временные ряды состоят из величин, измеряемых ежеквартально, ежемесячно, еженедельно, ежедневно и даже ежечасно. Как показано на рис. 2, если данные измеряются ежемесячно или ежеквартально, следует учитывать сезонный компонент. В этом разделе мы рассмотрим методы, позволяющие прогнозировать значения таких временных рядов.
В сценарии, описанном в начале главы, упоминалась компания Wal-Mart Stores, Inc. Рыночная капитализация компании 229 млрд. долл. Ее акции котируются на Нью-Йоркской фондовой бирже под аббревиатурой WMT. Финансовый год компании заканчивается 31 января, поэтому в четвертый квартал 2002 года включаются ноябрь и декабрь 2001 года, а также январь 2002 года. Временной ряд квартальных доходов компании приведен на рис. 22.

Рис. 22. Квартальные доходы компании Wal-Mart Stores, Inc. (млн. долл.)
Для таких квартальных рядов, как этот, классическая мультипликативная модель, кроме тренда, циклического и случайного компонента, содержит сезонный компонент: Y i = T i * S i * C i * I i
Прогнозирование месячных и временны х рядов с помощью метода наименьших квадратов. Регрессионная модель, включающая сезонный компонент, основана на комбинированном подходе. Для вычисления тренда применяется метод наименьших квадратов, описанный ранее, а для учета сезонного компонента - категорийная переменная (подробнее см. раздел Регрессионные модели с фиктивной переменной и эффекты взаимодействия ). Для аппроксимации временных рядов с учетом сезонных компонентов используется экспоненциальная модель. В модели, аппроксимирующей квартальный временной ряд, для учета четырех кварталов нам понадобились три фиктивные переменные Q 1 , Q 2 и Q 3 , а в модели для месячного временного ряда 12 месяцев представляются с помощью 11 фиктивных переменных. Поскольку в этих моделях в качестве отклика используется переменная logY i , а не Y i , для вычисления настоящих регрессионных коэффициентов необходимо выполнить обратное преобразование.
Чтобы проиллюстрировать процесс построения модели, аппроксимирующей квартальный временной ряд, вернемся к доходам компании Wal-Mart. Параметры экспоненциальной модели, полученные с помощью Пакета анализа Excel, показаны на рис. 23.

Рис. 23. Регрессионный анализ квартальных доходов компании Wal-Mart Stores, Inc.
Видно, что экспоненциальная модель довольно хорошо аппроксимирует исходные данные. Коэффициент смешанной корреляции r 2 равен 99,4% (ячейки J5), скорректированный коэффициент смешанной корреляции - 99,3% (ячейки J6), тестовая F -статистика - 1 333,51 (ячейки M12), а р -значение равно 0,0000. При уровне значимости α = 0,05, каждый регрессионный коэффициент в классической мультипликативной модели временного ряда является статистически значимым. Применяя к ним операцию потенцирования, получаем следующие параметры:

Коэффициенты ![]() интерпретируются следующим образом.
интерпретируются следующим образом.
Используя регрессионные коэффициенты b i , можно предсказать доход, полученный компанией в конкретном квартале. Например, предскажем доход компании для четвертого квартала 2002 года (X i = 35):
log = b 0 + b 1 Х i = 4,265 + 0,016*35 = 4,825
= 10 4,825 = 66 834
Таким образом, согласно прогнозу в четвертом квартале 2002 года компания должна была получить доход, равный 67 млрд. долл. (вряд ли следует делать прогноз с точностью до миллиона). Для того чтобы распространить прогноз на период времени, находящийся за пределами временного ряда, например, на первый квартал 2003 года (X i = 36, Q 1 = 1), необходимо выполнить следующие вычисления:
logŶ i = b 0 + b 1 Х i + b 2 Q 1 = 4,265 + 0,016*36 – 0,093*1 = 4,748
10 4,748 = 55 976
Индексы
Индексы используются в качестве индикаторов, реагирующих на изменения экономической ситуации или деловой активности. Существуют многочисленные разновидности индексов, в частности, индексы цен, количественные индексы, ценностные индексы и социологические индексы. В данном разделе мы рассмотрим лишь индекс цен. Индекс - величина некоторого экономического показателя (или группы показателей) в конкретный момент времени, выраженный в процентах от его значения в базовый момент времени.
Индекс цен. Простой индекс цен отражает процентное изменение цены товара (или группы товаров) в течение заданного периода времени по сравнению с ценой этого товара (или группы товаров) в конкретный момент времени в прошлом. При вычислении индекса цен прежде всего следует выбрать базовый промежуток времени - интервал времени в прошлом, с которым будут производиться сравнения. При выборе базового промежутка времени для конкретного индекса периоды экономической стабильности являются более предпочтительными по сравнению с периодами экономического подъема или спада. Кроме того, базовый промежуток не должен быть слишком удаленным во времени, чтобы на результаты сравнения не слишком сильно влияли изменения технологии и привычек потребителей. Индекс цен вычисляется по формуле:

где I i - индекс цен в i -м году, Р i - цена в i -м году, Р баз - цена в базовом году.
Индекс цен - процентное изменение цены товара (или группы товаров) в заданный период времени по отношению к цене товара в базовый момент времени. В качестве примера рассмотрим индекс цен на неэтилированный бензин в США в промежутке времени с 1980 по 2002 г. (рис. 24). Например:


Рис. 24. Цена галлона неэтилированного бензина и простой индекс цен в США с 1980 по 2002 г. (базовые годы - 1980 и 1995)
Итак, в 2002 г. цена неэтилированного бензина в США была на 4,8% больше, чем в 1980 г. Анализ рис. 24 показывает, что индекс цен в 1981 и 1982 гг. был больше индекса цен в 1980 г., а затем вплоть до 2000 года не превышал базового уровня. Поскольку в качестве базового периода выбран 1980 г., вероятно, имеет смысл выбрать более близкий год, например, 1995 г. Формула для пересчета индекса по отношению к новому базовому промежутку времени:

где I новый - новый индекс цен, I старый - старый индекс цен, I новая база – значение индекса цен в новом базовом году при расчете для старого базового года.
Предположим, что в качестве новой базы выбран 1995 год. Используя формулу (10), получаем новый индекс цен для 2002 года:
Итак, в 2002 г. неэтилированный бензин в США стоил на 13,9% больше, чем в 1995 г.
Невзвешенные составные индексы цен. Несмотря на то что индекс цен на любой отдельный товар представляет несомненный интерес, более важным является индекс цен на группу товаров, позволяющий оценить стоимость и уровень жизни большого количества потребителей. Невзвешенный составной индекс цен, определенный формулой (11), приписывает каждому отдельному виду товаров одинаковый вес. Составной индекс цен отражает процентное изменение цены группы товаров (часто называемой потребительской корзиной) в заданный период времени по отношению к цене этой группы товаров в базовый момент времени.

где t i - номер товара (1, 2, …, n ), n - количество товаров в рассматриваемой группе, - сумма цен на каждый из n товаров в период времени t , - сумма цен на каждый из n товаров в нулевой период времени, - величина невзвешенного составного индекса в период времени t .
На рис. 25 представлены средние цены на три вида фруктов за период с 1980 по 1999 гг. Для вычисления невзвешенного составного индекса цен в разные годы применяется формула (11), считая базовым 1980 год.
Итак, в 1999 г. суммарная цена фунта яблок, фунта бананов и фунта апельсинов на 59,4% превышала суммарную цену на эти фрукты в 1980 г.

Рис. 25. Цены (в долл.) на три вида фруктов и невзвешенный составной индекс цен
Невзвешенный составной индекс цен выражает изменения цен на всю группу товаров с течением времени. Несмотря на то что этот индекс легко вычислять, у него есть два явных недостатка. Во-первых, при вычислении этого индекса все виды товаров считаются одинаково важными, поэтому дорогие товары приобретают излишнее влияние на индекс. Во-вторых, не все товары потребляются одинаково интенсивно, поэтому изменения цен на мало потребляемые товары слишком сильно влияют на невзвешенный индекс.
Взвешенные составные индексы цен. Из-за недостатков невзвешенных индексов цен более предпочтительными являются взвешенные индексы цен, учитывающие различия цен и уровней потребления товаров, образующих потребительскую корзину. Существуют два типа взвешенных составных индексов цен. Индекс цен Лапейрэ , определенный формулой (12), использует уровни потребления в базовом году. Взвешенный составной индекс цен позволяет учесть уровни потребления товаров, образующих потребительскую корзину, присваивая каждому товару определенный вес.

где t - период времени (0, 1, 2, …), i - номер товара (1, 2, …, n ), n i в нулевой период времени, - значение индекса Лапейрэ в период времени t .
Вычисления индекса Лапейрэ показаны на рис. 26; в качестве базового используется 1980 год.

Рис. 26. Цены (в долл.), количество (потребление в фунтах на душу населения) трех видов фруктов и индекс Лапейрэ
Итак, индекс Лапейрэ в 1999 г. равен 154,2. Это свидетельствует от том, что в 1999 году эти три вида фруктов были на 54,2% дороже, чем в 1980 году. Обратите внимание на то, что этот индекс меньше невзвешенного индекса, равного 159,4, поскольку цены на апельсины - фрукты, потребляемые меньше остальных, - выросли больше, чем цена яблок и бананов. Иначе говоря, поскольку цены на фрукты, потребляемые наиболее интенсивно, выросли меньше, чем цены на апельсины, индекс Лапейрэ меньше невзвешенного составного индекса.
Индекс цен Пааше использует уровни потребления товара в текущем, а не базовом периоде времени. Следовательно, индекс Пааше более точно отражает полную стоимость потребления товаров в заданный момент времени. Однако этот индекс имеет два существенных недостатка. Во-первых, как правило, текущие уровни потребления трудно определить. По этой причине многие популярные индексы используют индекс Лапейрэ, а не индекс Пааше. Во-вторых, если цена некоторого конкретного товара, входящего в потребительскую корзину, резко возрастает, покупатели снижают уровень его потребления по необходимости, а не вследствие изменения вкусов. Индекс Пааше вычисляется по формуле:

где t - период времени (0, 1, 2, …), i - номер товара (1, 2, …, n ), n - количество товаров в рассматриваемой группе, - количество единиц товара i в нулевой период времени, - значение индекса Пааше в период времени t .
Вычисления индекса Пааше показаны на рис. 27; в качестве базового используется 1980 год.

Рис. 27. Цены (в долл.), количество (потребление в фунтах на душу населения) трех видов фруктов и индекс Пааше
Итак, индекс Пааше в 1999 г. равен 147,0. Это свидетельствует от том, что в 1999 году эти три вида фруктов были на 47,0% дороже, чем в 1980 году.
Некоторые популярные индексы цен. В бизнесе и экономике используется несколько индексов цен. Наиболее популярным является индекс потребительских цен (Consumer Index Price - CPI). Официально этот индекс называется CPI-U, чтобы подчеркнуть, что он вычисляется для городов (urban), хотя, как правило, его называют просто CPI. Этот индекс ежемесячно публикуется Бюро статистики труда (U. S. Bureau of Labor Statistics) в качестве основного инструмента для измерения стоимости жизни в США. Индекс потребительских цен является составным и взвешенным по методу Лапейрэ. При его вычислении используются цены 400 наиболее широко потребляемых продуктов, видов одежды, транспортных, медицинских и коммунальных услуг. В данный момент при вычислении этого индекса в качестве базового используется период 1982–1984 гг. (рис. 28). Важной функцией индекса CPI является его использование в качестве дефлятора. Индекс CPI используется для пересчета фактических цен в реальные путем умножения каждой цены на коэффициент 100/CPI. Расчеты показывают, что за последние 30 лет среднегодовые темпы инфляции в США составили 2,9%.

Рис. 28. Динамика Consumer Index Price; полные данные см. Excel-файл
Другим важным индексом цен, публикуемым Бюро статистики труда, является индекс цен производителей (Producer Price Index - PPI). Индекс PPI является взвешенным составным индексом, использующим метод Лапейрэ для оценки изменения цен товаров, продаваемых их производителями. Индекс PPI является лидирующим индикатором для индекса CPI. Иначе говоря, увеличение индекса PPI приводит к увеличению индекса CPI, и наоборот, уменьшение индекса PPI приводит к уменьшению индекса CPI. Финансовые индексы, такие как индекс Доу-Джонса для акций промышленных предприятий (Dow Jones Industrial Average - DJIA), S&P 500 и NASDAQ, используются для оценки изменения стоимости акций в США. Многие индексы позволяют оценить прибыльность международных фондовых рынков. К таким индексам относятся индекс Nikkei в Японии, Dax 30 в Германии и SSE Composite в Китае.
Ловушки, связанные с анализом временны х рядов
Значение методологии, использующей информацию о прошлом и настоящем для того, чтобы прогнозировать будущее, более двухсот лет назад красноречиво описал государственный деятель Патрик Генри: «У меня есть лишь одна лампа, освещающая путь, - мой опыт. Только знание прошлого позволяет судить о будущем».
Анализ временных рядов основан на предположении, что факторы, влиявшие на деловую активность в прошлом и влияющие в настоящем, будут действовать и в будущем. Если это правда, анализ временных рядов представляет собой эффективное средство прогнозирования и управления. Однако критики классических методов, основанных на анализе временных рядов, утверждают, что эти методы слишком наивны и примитивны. Иначе говоря, математическая модель, учитывающая факторы, действовавшие в прошлом, не должна механически экстраполировать тренды в будущее без учета экспертных оценок, опыта деловой активности, изменения технологии, а также привычек и потребностей людей. Пытаясь исправить это положение, в последние годы специалисты по эконометрии разрабатывали сложные компьютерные модели экономической активности, учитывающие перечисленные выше факторы.
Тем не менее, методы анализа временных рядов представляют собой превосходный инструмент прогнозирования (как краткосрочного, так и долгосрочного), если они применяются правильно, в сочетании с другими методами прогнозирования, а также с учетом экспертных оценок и опыта.
Резюме. В заметке с помощью анализа временных рядов разработаны модели для прогнозирования доходов трех компаний: Wm. Wrigley Jr. Company, Cabot Corporation и Wal-Mart. Описаны компоненты временного ряда, а также несколько подходов к прогнозированию годовых временных рядов - метод скользящих средних, метод экспоненциального сглаживания, линейная, квадратичная и экспоненциальная модели, а также авторегрессионная модель. Рассмотрена регрессионная модель, содержащая фиктивные переменные, соответствующие сезонному компоненту. Показано применение метода наименьших квадратов для прогнозирования месячных и квартальных временных рядов (рис. 29).
Р степеней свободы утрачиваются при сравнении значений временного ряда.


