Международный консорциум «Электронный университет»
Московский государственный университет экономики, статистики и информатики
Евразийский открытый институт
Н. А. Садовникова Р. А. Шмойлова
Анализ временных рядов и прогнозирование
Учебное пособие Руководство по изучению дисциплины
Практикум
Тесты Учебная программа
Москва 2004
С 143
Садовникова Н. А., Шмойлова Р.А. АНАЛИЗ ВРЕМЕННЫХ РЯДОВ И ПРОГ-
НОЗИРОВАНИЕ. Вып. 2: Учебное пособие, руководство по изучению дисциплины, практикум, тесты, учебная программа / Московский государственный университет экономики, статистики и информатики. - М., 2004. - 200 с.
1.1. Система статистических понятий и категорий, применяемых в моделировании и прогнозировании социально-экономических
явлений и процессов............................................................................................... | ||
1.2. Модель как отображение действительности........................................................ | ||
1.3. Понятие и основные принципы экономико-статистического анализа.............. | ||
1.4. Характеристика информационной базы и основные принципы | ||
ее формирования..................................................................................................... | ||
РАЗДЕЛ II. Моделирование динамики социально-экономических явлений | ||
2.1. Временные ряды, их характеристики и задачи анализа. | ||
Требования к исходной информации. .................................................................. | ||
2.2. Основные особенности статистического анализа одномерных | ||
временных рядов по компонентам ряда. .............................................................. | ||
Моделирование тенденции.................................................................................... | ||
Выбор формы тренда.............................................................................................. | ||
Моделирование случайного компонента............................................................. | ||
Модели периодических колебаний....................................................................... | ||
2.7. Модели связных временных рядов....................................................................... | ||
КОНТРОЛЬНЫЕ ВОПРОСЫ К РАЗДЕЛУ II..................................................................... | ||
РАЗДЕЛ III. Прогнозирование динамики социально-экономических явлений | ||
и процессов.................................................................................................... | ||
3.1. Сущность и классификация статистических прогнозов..................................... | ||
Простейшие методы прогнозирования................................................................. | ||
3.3. Прогнозирование на основе экстраполяции тренда............................................ | ||
3.4. Прогнозирование с учетом дисконтирования информации............................... | ||
3.5. Прогнозирование на основе кривых роста........................................................... | ||
3.6. Прогнозирование рядов динамики, не имеющих тенденции............................. | ||
3.7. Оценка точности и надежности прогнозов.......................................................... | ||
КОНТРОЛЬНЫЕ ВОПРОСЫ К РАЗДЕЛУ III ................................................................... | ||
ТЕСТЫ ДЛЯ САМОПРОВЕРКИ......................................................................................... | ||
КОНТРОЛЬНАЯ РАБОТА................................................................................................... | ||
Приложения к контрольной работе..................................................................................... | ||
ГЛОССАРИЙ......................................................................................................................... | |
Заключение............................................................................................................................. | |
Приложения............................................................................................................................ | |
РУКОВОДСТВО ПО ИЗУЧЕНИЮ ДИСЦИПЛИНЫ................................................. | |
ПРАКТИКУМ....................................................................................................................... | |
ТЕСТЫ.................................................................................................................................. | |
УЧЕБНАЯ ПРОГРАММА................................................................................................. |
Учебное пособие
ВВЕДЕНИЕ
Введение
Развитие и повышение социально-экономического статуса и положения страны выдвигает на первый план задачу анализа и перспектив развития субъектов рыночных отношений на различных иерархических уровнях управления с целью выбора оптимальных управленческих решений, направленных на повышение эффективности и деловой активности их функционирования.
В этой связи возрастает роль методологии статистического моделирования и прогнозирования состояния, структуры и основных тенденций развития субъектов рыночных отношений вне зависимости от отраслевой принадлежности, форм собственности и внутренней структурной градации.
Учебное пособие «Анализ временных рядов и прогнозирование» включает в себя комплексную методологию моделирования и прогнозирования динамической информации, представленнойвременными рядами социально-экономических явлений и процессов.
В пособии нашло отражение обобщение отечественного и зарубежного опыта использования математико-статистических методов моделирования и прогнозирования со- циально-экономических явлений и процессов.
Важнейшая задача прогнозирования явлений и процессов - выявление закономерностей и установление основных тенденций развития. Для анализа общих тенденций не целесообразно рассматривать каждый случай в отдельности. Чем больше по числу единиц статистическая совокупность, тем, при прочих равных условиях, качественнее проявляется закономерность, присущая изучаемому явлению или процессу.
Устойчивые пропорции в экономических явлениях и процессах проявляются при действии закона больших чисел.
Моделирование и прогнозирование позволяют управлять массовыми экономическими явлениями и процессами и предвидеть их развитие.
Для моделирования и прогнозирования социально-экономических явлений и процессов решающее значение имеет принцип взаимной связи и взаимной обусловленности явлений. Для того, чтобы глубоко понять явление, необходимо изучить внешние и внутренние причинные взаимосвязи, познать конкретное состояние и условия его возникновения и существования.
Общественные явления находятся не только во взаимной связи, но и в непрерывном движении, изменении, развитии - именно это обусловливает необходимость прогнозирования.
Предметом моделирования и прогнозирования в сфере бизнеса является система, воспроизводящая объект исследования так, что на ее основе могут быть изучены структура и размещение социально-экономических явлений, их изменения во времени, связи и зависимости.
При моделировании объект, интересующий исследователя, заменяется некоторым другим объектом, который называется моделью.
Каковы же объективные основания замены одного объекта другим?
Предметы материального мира - целостные системы свойств, связей, отношений, процессов. Закономерная связь элементов является объективной основой моделирования и прогнозирования.
Элементы включены в совокупности не случайно, а закономерно координированы друг с другом, и, если два объекта сходны в каком-то существенном отношении, то они будут сходны и в другом отношении. Отсюда следует, что объектом моделирования и прогнозирования в сфере бизнеса являются статистические совокупности, их численность.
ВВЕДЕНИЕ
РАЗДЕЛ I. Теоретико-методологические аспекты моделирования явлений и процессов в сфере бизнеса
1. 1. Система статистических понятий и категорий, применяемых в моделировании и прогнозировании социально-экономических явлений и процессов
Моделирование и прогнозирование явлений и процессов предполагает использование системы статистических понятий, категорий и методов, трактовка которых углубляется в соответствии с их статистическими особенностями.
К важнейшим понятиям и категориям относится статистическая совокупность, статистическая закономерность, закон больших чисел, статистическая взаимосвязь, а также такие философские категории как качество и количество, мера, явление и сущность, единичное и всеобщее, случайное и необходимое.
Важнейшими методами, используемыми при моделировании социально-экономи- ческих явлений, являются методы статистического наблюдения, группировок, обобщающих показателей, корреляционного и регрессионного анализа и так далее.
Статистическая закономерность выражает конкретные казуальные отношения, она предопределяет типичное распределение единиц статистической совокупности на некоторый моментвремениподвоздействиемвсейсовокупностифакторов.
Условиями ее проявления являются: наличие статистической совокупности и действие закона больших чисел.
Зная статистическую закономерность, можно выявить условия и причины, порождающие ее, для того, чтобы направлять ее действия в заданное «русло», то есть либо поддерживать эти условия для ее устойчивости во времени, либо, меняя их, стремиться получить нужный результат.
Зная статистическую закономерность, можно с той или иной степенью точности предсказать развитие явления, раскрыть сущность и изучить его структуру.
Под статистической совокупностью (множеством) понимается множество единиц, обладающих массовостью, однородностью, определенной целостностью, взаимозависимостью состояний отдельных единиц и наличием вариации.
Статистические совокупности состоят из элементов, единиц совокупности, которые являются носителем свойств изучаемого явления или процесса.
Признаки бывают существенные и несущественные, прямые и косвенные, атрибутивные и количественные, первичные и вторичные, факторные и результативные, альтернативные.
Классификация статистических признаков имеет важное значение для построения статистических моделей и осуществления прогноза. Так, при моделировании в ряде случаев важно правильно выделить факторные и результативные признаки. Среди факторных признаков необходимо отбирать лишь самые существенные, определяющие основное содержание явлений.
Закон больших чисел выявляет устойчивые пропорции и соотношения в экономических явлениях и процессах. Он служит основой для моделирования процессов, создает возможность управлять ими и предвидеть их развитие.
Закон больших чисел определяет общее, существенное в явлениях, в их массе единиц, благодаря чему происходит взаимоотношение индивидуальных случайных различий.
Итак, моделирование - воспроизведение свойств исследуемого объекта в специально построенной модели. Для этой цели используются такие статистические методы
ГЛАВА I. ТЕОРЕТИКО-МЕТОДОЛОГИЧЕСКИЕ АСПЕКТЫ МОДЕЛИРОВАНИЯ ЯВЛЕНИЙ И ПРОЦЕССОВ В СФЕРЕ БИЗНЕСА
как статистическое наблюдение, метод группировок, обобщающих показателей, корреляционный и регрессионный анализ.
С помощью статистического наблюдения и социального эксперимента получают исходную информацию для моделирования и прогнозирования.
Метод группировок устанавливает наличие и направление связи между факторными и результативными признаками. Для объективных заключений о связи необходимо предварительно определить границу, за пределами которой влияние группировочного признака отсутствует.
На основе регрессионного и корреляционного анализа связи получают свое аналитическое выражение, устанавливается теснота связей между факторными и результативными признаками.
Значимость корреляционных характеристик определяется объективными особенностями исследуемой совокупности, а показатели регрессии и корреляции вычисляются как средние величины для совокупности в целом.
1.2. Модель как отображение действительности
Наши представления об окружающей действительности по природе своей являются приближенными копиями объективной реальности.
Термин «модель» отражает как раз эту условность, приблизительность знания об объективной действительности.
Что же такое модель?
В «Философском словаре» дается следующее определение: « Моделирование - воспроизведение свойств исследуемого объекта на специально построенном по определенным правилам аналоге его. Этот аналог называется моделью».
В «Философской энциклопедии» говорится: « Модель - условный образ (изображение, схема, описание) какого-либо объекта (или системы объектов) служит для выражения отношения между человеческими знаниями об объектах и этими объектами».
Таким образом, под моделью понимается условный образ какого-либо объекта, приближенно воссоздающий этот объект. Между объектом и его моделью существуют отношения сходства, условности.
Модель дает возможность установить в каждом явлении, объекте, процессе те основные, главные закономерности, которые присущи этим явлениям.
Отношения объекта и модели устанавливаются на основе объективно присущих оригиналу и модели свойств и отношений.
Прежде всего между моделью и объектом существует отношение соответствия (сходства), которое и позволяет исследовать моделируемый объект посредством изучения модели.
Но модель используется и для получения таких данных об объекте, которые или затруднительно, или невозможно получить путем непосредственного изучения оригинала. Для того, чтобы модель могла выполнить эту задачу, она должна быть не только сходной с оригиналом, но иотличаться от него. Отличие от оригинала - обязательный признак модели.
В процессе моделирования от установления отношений сходства между одними элементами модели и оригинала переходим к установлению отношений сходства между другими элементами оригинала и модели. Именно наличие такого перехода дает возможность получить новые данные об оригинале, о его свойствах, связях и отношениях.
Возможны два направления в моделировании.
ГЛАВА I. ТЕОРЕТИКО-МЕТОДОЛОГИЧЕСКИЕ АСПЕКТЫ МОДЕЛИРОВАНИЯ ЯВЛЕНИЙ И ПРОЦЕССОВ В СФЕРЕ БИЗНЕСА
Одно из направлений охватывает множество задач, в которых основное внимание уделено отысканию оптимальных характеристик процесса.
В качестве таких моделей часто выступают модели линейного программирования. Эти модели часто называют экономико-математическими , поскольку их применение связано главным образом с моделированием функциональных зависимостей.
Сущность статистического моделирования состоит в построении для данного явления модели, на основании которой изучается поведение элементов системы и взаимодействие между ними с учетом многих, имеющих случайный характер, факторов. Данное направление включает всебя корреляционный анализ, изучение законов распределения и другие.
Модели, выражающие количественно закономерность, которая проявляется в массе событий, называют экономико-статистическими моделями .
Повышенный интерес, проявляемый в последние годы к статистическим моделям, обусловлен наличием электронно-вычислительных машин, позволяющих обрабатывать большие массивы информации.
Статистические модели можно подразделить на два типа: статистические и временные . В первом случае речь идет об исследовании статистической совокупности. Единицей наблюдения здесь служат отдельные единицы пространственной совокупности, а в качестве статистической информации используются их показатели по состоянию на определенный период времени.
Временная модель рассматривает процесс изменения явления во времени. В качестве единицы наблюдения здесь выступает время, а исходной информацией служат ряды динамики явления и определяющие его факторы.
По своим познавательным функциям статистические модели подразделяются на
структурные, динамические и модели взаимосвязей.
1.3. Понятие и основные принципы экономико-статистического анализа
Анализ и обобщение данных исследования - заключительный этап статистического исследования, конечной целью которого является получение теоретических выводов и практических заключений о тенденциях и закономерностях изучаемых социальноэкономических явлений и процессов.
Анализ - это метод научного исследования объекта путем рассмотрения его отдельных сторон и составных частей.
Экономико-статистический анализ - это разработка методики, основанной на широком применении традиционных статистических и математико-статистических методов с целью контроля адекватного отражения исследуемых явлений и процессов.
Задачами анализа являются: определение и оценка специфики и особенностей изучаемых явлений и процессов, изучение их структуры, взаимосвязей и закономерностей их развития.
В качестве этапов статистического анализа выделяются:
1) формулировка цели анализа;
2) критическая оценка данных;
3) сравнительная оценка и обеспечение сопоставимости данных;
4) формирование обобщающих показателей;
5) фиксация и обоснование существенных свойств, особенностей, сходств и различий, связей и закономерностей изучаемых явлений и процессов;
6) формулировка заключений, выводов и практических предложений о резервах и перспективах развития изучаемого явления.
В этой статье попытаемся дать общее представление о статистических методах прогнозирования временных рядов .
Прогноз – возможное состояние объекта в будущем, а также суждение об альтернативных путях достижения этого состояния в будущем.
Классификация прогнозов
:
По масштабности выделяют следующие прогнозы:
- Прогнозы микроуровня
- Прогнозы макроуровня
- Глобальные прогнозы
По времени прогнозы делят на:
- Краткосрочные
- Среднесрочные
- Долгосрочные
Это довольно условное деление, так как деление производит эксперт, изучающий временные ряды.
Прогнозирование можно рассматривать на двух уровнях:
- Прогнозирование как предсказание
- Прогнозирование как предуказание
Предсказание
– отвечает на вопрос «что нам ожидать в будущем?», описывает перспективы изменения объекта исследования в будущем. (Такие прогнозы называют поисковыми
)
Предуказание
– отвечает на вопрос «что нам нужно изменить в будущем, что бы получить заданное состояние объекта?», возможное решение проблем, возникающих при предсказании. (Такие прогнозы называют нормативными
).
Этапы прогнозирования включают в себя следующие уровни:
- Сбор необходимой задачи для прогноза
- Предобработка данных
- Определение моделей прогнозирования
- Оценка параметров выбранных моделей
- Проверка на адекватность выбранной модели
- Выбор лучшей модели для прогнозирования
- Построение прогноза по выбранной модели
- Анализ результатов
Изменение экономико-финансовых показателей чаще всего отражается временными
и динамическими
рядами.
Динамические ряды
– совокупность последовательных наблюдений показателя х в зависимости от изменения показателя y.
Временные ряды
– называют совокупность последовательных наблюдений, упорядоченных во временной последовательности.
Рисунок 1. Пример временного ряда
Временные ряды можно разделить на моментные
и интервальные ряды
. Моментные временные ряды – наблюдения характеризуют объект на определенный момент времени. Интервальные временные ряды – ряд наблюдений характеризует объект за определенный период времени.
Процесс прогнозирования финансово-экономических рядов состоит в определении и выделении закономерностей, которые объясняли динамику изменения процесса в прошлом, для того чтобы потом использовать ее для описания ее развития в будущем. Для успешного осуществления процесса прогнозирования необходимо, что бы анализируемый временной ряд был достаточной длины
(свойство полноты информации
), во временном ряде не должно быть пропусков
(свойство непрерывности
). Соответствие изучаемого временного ряда этим требованиям проверяется на этапе «Предварительная обработка данных».
Давайте рассмотрим компоненты временного ряда.
- Трендовая - T
- Сезонная - S
- Циклическая -C
- Нерегулярная - e
Тренд
– направленное изменение значений наблюдаемого временного ряда. Наряду с трендовыми движениями, в экономических процессах часто присутствует сезонная
составляющая, которая представляет период колебания показателей, не превышающих 1 год. Если период более 1 года, то говорят, что во временном ряду присутствует циклическая
составляющая. Если из изучаемого ряда убрать трендовую составляющую и периодическую (циклическая и сезонная), то останется нерегулярная, случайная компонента.
Если временной ряд равен сумме своих компонент
Y=T+S+C+e,
то полученная модель ряда называется аддитивной
, если в виде произведения
Y=T*S*C*e,
то это мультипликативная
модель.
Смешанный тип модели временного ряда соответственно представлен формулой
Y=T*S*C+e, где Y-значение временного ряда.
Если все компоненты во временном ряду правильно выделены, то случайная недетерминированная, некоррелированная компонента е
обладает следующими свойствами:
- е – является случайными величинами
- случайные величины распределены по нормальному закону распределения
- имеет математическое ожидание равно 0
Предобработка временных рядов

Аномальные наблюдения могут возникнуть из-за ошибок в измерении и передачи информации (ошибки первого рода – подлежат устранению) или воздействия на изучаемый процесс редко появляющихся объективных факторов (ошибки второго рода – не подлежат устранению).
Устранение аномальных наблюдений производится в 2 этапа: поиск аномальных наблюдений по методу Ирвинга и замена их на среднее арифметическое соседних значений.


Одним из самых распространённых методов сглаживания временных рядов является метод скользящей средней.
Суть использования метода заключается в замене значений временного ряда на более сглаженные значения, подверженные колебаниям в меньшей степени. Скользящие средние позволяют выявить тенденцию в развитии процесса и отфильтровать компоненты временного ряда, а также подготовить данные для построения модели прогнозирования.
Сглаживание может производиться следующими методами:
- Простой скользящей средней (SMA)
- Взвешенной скользящей средней (WMA)
- Экспоненциальной скользящей средней (EMA)
- Критерий восходящих/нисходящих серий Кокса-Стюарта
- Критерий серий (основанный на медиане выборки)
- Метод Фостера-Стюарта
- Метод автокорреляционных функций
Расчет количественных характеристик развития экономических процессов включает в себя определение: расчета абсолютных приростов , расчета темпов роста , выявления автокорреляции временного ряда. В основе вычисления этих показателей лежит сравнение значений временного ряда. Такой подход к анализу и прогнозированию процесса применим, если изучаемый временной ряд имеет линейную тенденцию. К недостаткам такого анализа следует отнести то, что в нем учитывается только конечные и начальные значения временного ряда и исключается влияние промежуточных данных.
Построение моделей временных рядов
Формирование значений временного ряда определяется тремя закономерностями:
- Инерцией тенденции
- Инерцией взаимосвязи между последовательными значениями временного ряда
- Инерцией взаимосвязи между исследуемым показателем и показателями – факторами, оказывающие на него воздействие
В соответствии с этими закономерностями выделяют задачи анализа и моделирования тенденций (решается с помощью моделей кривых роста
), анализа взаимосвязи между значениями временного ряда (решается с помощью адаптивных моделей
), анализа причинных взаимодействий между исследуемым показателем и показателями – факторами (решается регрессионными методами
).
Кривая роста
– плавная кривая, аппроксимирующая временной ряд. Аналитические методы выделения неслучайной составляющей временного ряда с помощью кривых роста реализуется в рамкам модели регрессии.
Процедура
разработки прогноза по кривым роста:
- Выбор кривой роста
- Оценка параметров выбранной кривой
- Расчет точного и интервального прогноза
- Оценка полученного прогноза
Кривые роста делятся на три класса. К первому классу относят кривые для описания монотонных процессов развития объекта. Ко второму классу относят кривые, которые описывают процессы с пределом роста в исследуемом периоде (их называют кривые насыщения ). Если кривые насыщения имеют точку перегиба, то они относятся к 3му классу S – образных кривых.

1 класс
кривых роста включает – полином первого порядка, второго, третьего, экспоненту, экспоненциальные кривые.
2 класс
кривых роста включает – модифицированную экспоненту.
3 класс
кривых – Кривая Гомперца, логистическая кривая.
Наиболее простой способ выбрать кривую роста – визуальный
метод. Подбирают кривую, наиболее точно описывающую исследуемый процесс.
Оценка качества полученной модели для прогнозирования по кривым роста производится при проверке адекватности и оценки точности модели
.
В проверку адекватности входит: проверка независимости (отсутствие автокорреляции по критерию Дарбина-Уотсона), проверка случайности, соответствие остатков временного ряда случайному распределению(R/S критерий), равенство 0 средней ошибки.
Точность модели оценивается по методу МНК
, т.е. кривая подбирается таким образом, чтобы график функции кривой роста располагался на минимальном удалении от точек процесса.
Данные за прошлые периоды можно использовать для прогнозирования.
Множество данных, где время является независимой переменной, называется временным рядом .
Общее изменение со временем результативного признака называется трендом . Мы рассмотрим модели линейного тренда , то есть параметры тренда модно рассчитать с помощью модели линейной регрессии.
Сезонная вариация – это повторение данных через небольшой промежуток времени. Под «сезоном» можно понимать день, и неделю, и месяц, и квартал. Если же промежуток времени будет длительным, то это – циклическая вариация . Мы остановимся на изучении данных для небольших интервалов времени, поэтому циклическую вариацию исключим из рассмотрения.
Сначала
на основании прошлых данных определяется
сезонная вариация. Исключив сезонную
вариацию (проведя так называемую
десезонализацию
данных
), с
помощью модели линейной регрессии
находим уравнение тренда. По уравнению
тренда и прошлым данным вычисляем
величины ошибок. Это среднее абсолютное
отклонение
 ,
где
,
где
 - это разность фактического и прогнозного
значений в момент времениt
, n
– число наблюдений.
- это разность фактического и прогнозного
значений в момент времениt
, n
– число наблюдений.
Анализ аддитивной модели.
Для аддитивной модели фактическое значение фактическое значение A = трендовое значение T + сезонная вариация S + ошибка E .
Пример 50 . Предположим, что нам известен объем прожаж (тыс. руб.) за последние 11 кварталов. Дадим на основании этих данных прогноз объема продаж на следующие два квартала.
|
Номер квартала |
Объем продаж |
Оценка сезонной вариации |
||
Заполним следующую таблицу. Оценки сезонной вариации запишем под соответствующим номером квартала году. В каждом столбце вычисляем среднее значение оценок сезонной вариации = (сумма чисел в столбце)/ (количество чисел в столбце). Результат запишем в строке «Среднее» (округления взяты до одной цифры после запятой). Сумма чисел в строке «Среднее» = -1.
Скорректируем значения в строке «Среднее», чтобы общая сумма была равна 0. Это необходимо, чтобы усреднить значения сезонной вариации в целом за год. Корректирующий фактор вычисляется следующим образом: сумма оценок сезонных вариаций (-1) делится на число кварталов в году (4). Поэтому из каждого числа этой строки нужно вычесть -1/4= -0,25. Так как у нас округления до одной цифры после запятой, то из нечетных столбцов вычтем -0,3, а из четных столбцов вычтем -0,2. В последней строке получены значения сезонной вариации для соответствующего квартала года.
|
Номер квартала в году | ||||||
|
Номер квартала |
Объем продаж |
Сезонная вариация |
A - S = T + E |
Уравнение
линии тренда T
=
a
+
b
*
x
,
где
 -
номерi
-
го квартала.
-
номерi
-
го квартала.
Найдем коэффициенты a и b


где
 -
номерi
-
го квартала, а
-
номерi
-
го квартала, а
 -
значение сезонной вариацииi
-
го квартала.
-
значение сезонной вариацииi
-
го квартала.
|
Номер квартала |
x 2 | |||
a =1,9 и b =1,1.
T = 1,9+ 1,1 x .
 i
i
 ,
где
,
где
 -
объем продаж,
-
объем продаж, -
сезонная вариация,
-
сезонная вариация, -
трендовое значение вi
-ом
квартале.
-
трендовое значение вi
-ом
квартале.
i x
Составим таблицу
|
Объем продаж A |
Десезонализированный объем продаж A - S = T + E |
Трендовое значение |
Ошибка
|
|
|
|



И среднеквадратическая ошибка
Прогноз объема продаж в 12-м квартале: (1,9+1,1*12)+(-0,9)=14,2 тыс.руб.
Прогноз объема продаж в 13-м квартале: (1,9+1,1*13)+2=18,2 тыс.руб.
Задача 50. В таблице указан объем продаж (тыс. руб.) за последние 11 кварталов. Дать на основании этих данных прогноз объема продаж на следующие два квартала.
На первом шаге нужно исключить влияние сезонной вариации. Воспользуемся методом скользящей средней. Заполним таблицу.
|
Номер квартала |
Объем продаж |
Скользящая средняя за 4 квартала |
Центрированная скользящая средняя |
Оценка сезонной вариации |
1 год = 4 квартала. Поэтому найдем среднее значение объема продаж за 4 последовательных квартала. Для этого нужно сложить 4 последовательных числа из 2-го столбца (объем продаж), эту сумму умножить на 4 (количество слагаемых) и результат записать в 3-й столбец напротив 3-го слагаемого.
Если при заполнении 3-го скользящая средняя вычислялась для четного числа сезонов, то вычисляется центрированная скользящая средняя по следующему правилу: полусумму двух соседних чисел из 3-го столбца запишем в четвертый столбец напротив верхнего из них. В противном случае (если скользящая средняя вычислялась для нечетного числа сезонов) центрированную скользящую среднюю вычислять не надо.
5-й столбец (оценка сезонной вариации) – это разность объема продаж и скользящей средней, в случае если последняя вычислялась для нечетно числа сезонов или разность объема продаж и центрированной скользящей средней в противном случае.
Заполним следующую таблицу. Оценки сезонной вариации запишем под соответствующим номером квартала году. В каждом столбце вычисляем среднее значение оценок сезонной вариации = (сумма чисел в столбце)/ (количество чисел в столбце). Результат запишем в строке «Среднее» (округления взяты до одной цифры после запятой). Сумма чисел в строке «Среднее» .
Скорректируем значения в строке «Среднее», чтобы общая сумма была равна 0. Это необходимо, чтобы усреднить значения сезонной вариации в целом за год. Корректирующий фактор вычисляется следующим образом: сумма оценок сезонных вариаций. Поэтому из каждого числа этой строки нужно вычесть = 0,593. В последней строке получены значения сезонной вариации для соответствующего квартала года.
|
Номер квартала в году | ||||||
|
Скорректированная сезонная вариация | ||||||
Исключим сезонную вариацию из фактических данных. Проведем десезонализацию данных.
|
Номер квартала |
Объем продаж |
Сезонная вариация |
Десезонализированный объем продаж A - S = T + E |
Из чисел 2-го столбца вычитаем числа 3-го столбца и результат пишем в 4-м столбце.
Уравнение
линии тренда T
=
a
+
b
*
x
,
где
 -
номерi
-
го квартала.
-
номерi
-
го квартала.
Найдем коэффициенты a и b по данным следующим формулам:


где
 -
номерi
-
го квартала, а
-
номерi
-
го квартала, а
 -
значение сезонной вариацииi
-
го квартала.
-
значение сезонной вариацииi
-
го квартала.
Для упрощения расчетов по указанным формулам заполним таблицу
|
Номер квартала |
x 2 | |||
Подставляя соответствующие данные из таблицы в приведенные выше формулы получим: a =1,97 и b =1,12.
Итак, уравнение тренда запишется так T = 1,97+ 1,12 x .
Теперь займемся расчетом ошибок.
Для
этого необходимо найти величины
 -
разность фактического и прогнозного
значения вi
-ом
квартале по следующей формуле:
-
разность фактического и прогнозного
значения вi
-ом
квартале по следующей формуле:
 ,
где
,
где
 -
объем продаж,
-
объем продаж, -
сезонная вариация,
-
сезонная вариация, -
трендовое значение вi
-ом
квартале.
-
трендовое значение вi
-ом
квартале.
Чтобы вычислить трендовое значение в i -ом квартале воспользуемся соответствующей формулой приведенной выше подставляя в нее вместо x номер соответствующего квартала.
Составим таблицу
|
Объем продаж A |
Десезонализированный объем продаж A - S = T + E |
Трендовое значение |
Ошибка
|
|
|
|



Среднее абсолютное отклонение и среднеквадратическая ошибка . Мы видим, что ошибки достаточно велики. Это скажется на качестве прогноза.
Дадим прогноз объема продаж на следующие два квартала.
прогноз = трендовое значение + скорректированная сезонная вариация.
Мы считаем, что тенденция, выявленная по прошлым данным, сохранится и в ближайшем будущем. Подставляем номера кварталов в формулу и учитываем скорректированную сезонную вариацию. T = 1,97+ 1,12 x .
Прогноз объема продаж в 12-м квартале: (1,97+1,12*12)+(-0,453)=14,957 тыс.руб.
Прогноз объема продаж в 13-м квартале: (1,97+1,12*13)+ 1,047=17,577 тыс.руб.
Анализ временных рядов позволяет изучить показатели во времени. Временной ряд – это числовые значения статистического показателя, расположенные в хронологическом порядке.
Подобные данные распространены в самых разных сферах человеческой деятельности: ежедневные цены акций, курсов валют, ежеквартальные, годовые объемы продаж, производства и т.д. Типичный временной ряд в метеорологии, например, ежемесячный объем осадков.
Временные ряды в Excel
Если фиксировать значения какого-то процесса через определенные промежутки времени, то получатся элементы временного ряда. Их изменчивость пытаются разделить на закономерную и случайную составляющие. Закономерные изменения членов ряда, как правило, предсказуемы.
Сделаем анализ временных рядов в Excel. Пример: торговая сеть анализирует данные о продажах товаров магазинами, находящимися в городах с населением менее 50 000 человек. Период – 2012-2015 гг. Задача – выявить основную тенденцию развития.
Внесем данные о реализации в таблицу Excel:
На вкладке «Данные» нажимаем кнопку «Анализ данных». Если она не видна, заходим в меню. «Параметры Excel» - «Надстройки». Внизу нажимаем «Перейти» к «Надстройкам Excel» и выбираем «Пакет анализа».
Подключение настройки «Анализ данных» детально описано .
Нужная кнопка появится на ленте.

Из предлагаемого списка инструментов для статистического анализа выбираем «Экспоненциальное сглаживание». Этот метод выравнивания подходит для нашего динамического ряда, значения которого сильно колеблются.
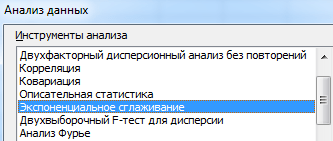
Заполняем диалоговое окно. Входной интервал – диапазон со значениями продаж. Фактор затухания – коэффициент экспоненциального сглаживания (по умолчанию – 0,3). Выходной интервал – ссылка на верхнюю левую ячейку выходного диапазона. Сюда программа поместит сглаженные уровни и размер определит самостоятельно. Ставим галочки «Вывод графика», «Стандартные погрешности».
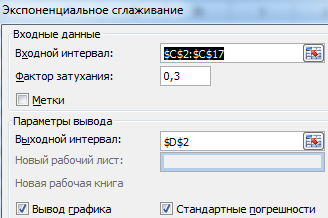
Закрываем диалоговое окно нажатием ОК. Результаты анализа:

Для расчета стандартных погрешностей Excel использует формулу: =КОРЕНЬ(СУММКВРАЗН(‘диапазон фактических значений’; ‘диапазон прогнозных значений’)/ ‘размер окна сглаживания’). Например, =КОРЕНЬ(СУММКВРАЗН(C3:C5;D3:D5)/3).
Прогнозирование временного ряда в Excel
Составим прогноз продаж, используя данные из предыдущего примера.
На график, отображающий фактические объемы реализации продукции, добавим линию тренда (правая кнопка по графику – «Добавить линию тренда»).
Настраиваем параметры линии тренда:

Выбираем полиномиальный тренд, что максимально сократить ошибку прогнозной модели.

R2 = 0,9567, что означает: данное отношение объясняет 95,67% изменений объемов продаж с течением времени.
Уравнение тренда – это модель формулы для расчета прогнозных значений.

Получаем достаточно оптимистичный результат:

В нашем примере все-таки экспоненциальная зависимость. Поэтому при построении линейного тренда больше ошибок и неточностей.
Для прогнозирования экспоненциальной зависимости в Excel можно использовать также функцию РОСТ.
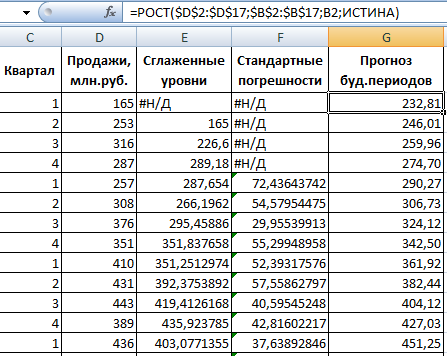
Для линейной зависимости – ТЕНДЕНЦИЯ.
При составлении прогнозов нельзя использовать какой-то один метод: велика вероятность больших отклонений и неточностей.
4 января 2011 в 21:36Прогнозирование временных рядов
- Алгоритмы
Привет.
Я хочу рассказать об одной задаче, которая очень заинтересовала меня в свое время, а именно, о задаче прогнозирования временных рядов и решении этой задачи методом муравьиного алгоритма.
Для начала вкратце о задаче и о самом алгоритме:
Прогнозирование временных рядов подразумевает, что известно значение некой функции в первых n точках временного ряда. Используя эту информацию необходимо спрогнозировать значение в n+1 точке временного ряда. Существует множество различных методов прогнозирования, но на сегодняшний день одними из самых распространенных являются метод Винтерса и ARIMA модель. Подробнее о них можно почитать .
О том что такое муравьиный алгоритм говорилось уже довольно много. Для тех кому лень лезть, например, сюда , перескажу. Вкратце, муравьиный алгоритм это моделирование поведения муравьиной колонии в их стремлении найти кратчайший путь к источнику еды. Муравьи, при движении оставляют за собой след феромона, который влияет на вероятность выбора муравьем данного пути. Учитывая то, что муравьи будут за один и тот же промежуток времени пройти короткий путь бОльшее количество раз, на нем будет оставаться больше феромона. Таким образом, с течением времени, все больше муравьев будут выбирать кратчайший путь к источнику пищи.
Для наглядности, вставлю картинку:
Теперь, перейдем непосредственно к решению задачи прогнозирования методом муравьиных колоний.
Первая проблема с которой мы сталкиваемся - необходимо представить временной ряд в виде графа, на котором будем запускать муравьиный алгоритм.
Было найдено два возможных решения:
1. Представить временной ряд в виде мультиграфа где из каждой точки временного ряда можно перейти в каждую набором определенных приростов. (Для облегчения задачи будем брать нормализованные значения на промежутке от -1 до 1). Это был первый подход, который мы попробовали. Он показал неплохой результат на временных рядах малой размерности, но с увеличением размерности стала резко падать как точность прогноза, так и производительность, поэтому от этого варианта отказались.
2. Представить временной ряд в виде набора сцепленых графов, где каждый граф отвечает за свою величину прироста значения временного ряда. иначе говоря, имеем граф который отвечает за прирост -1, -0,9… и так до 1. Шаг, естественно, можно уменьшить, или увеличить, что скажется на точности прогноза и ресурсоемкости задачи.(в конечном итоге этот вариант оказался наиболее удачным.)
На этом наборе сцепленных графов, запускался муравьиный алгоритм(на каждом графе свой), который откладывал феромон на ребрах, соответствующих известным значениям временного ряда. Причем, при откладывании феромона на графе i, феромон также откладывался на графах i-1и i+1, но в гораздо меньшем количестве(в нашем случае 1/10 от базового количества феромона) таким образом, муравьи выделяли наиболее часто встречающиеся последовательности прироста значения временного ряда, а за счет откладывания феромона на смежные графы, нивелировалась возможная погрешность и изначальная зашумленность временного ряда.
Данный алгоритм мы тестировали на искусственно подготовленных временных рядах с разным уровнем периодичности и шума. Результат получился двояким. С одной стороны, при уровнях шума до 0,3 алгоритм показывает высокие результаты прогноза, сравнимые с результатами ARIMA модели. На более высоких уровнях шума возникает большой разброс результатов: прогноз то очень точный, то совершенно неправильный.
В настоящий момент мы работаем над подбором оптимального значения параметров алгоритма и некоторыми методами его улучшения, о которых я напишу как только они будут в достаточной степени проверены.
Спасибо всем за внимание.
Upd:
Постараюсь ответить на возникшие вопросы.
Мультиграф - это граф, каждая вершина которого соединена с каждой.
Хаотические ряды, как уже писали ниже, не случайны. Вы можете посмотреть на изображения ряда Лоренца в 3-х мерном пространстве и увидите цикличность движения. Просто определить эту цикличность сложно, и на первый взгляд ряд выглядит случайным.
Значения временного ряда нормализуются на промежутке -1...1 и записываются в граф. Граф - в данном случае таблица переходов из вершины в вершину. Феромон откладывается на ребра(в ячейки таблицы).
В случае со сцепленными графами используется несколько таблиц, каждая из которых отвечает только за свою величину перехода.
В зависимости от количества феромона в той, или иной ячейке, выбирается то, или иное значение временного ряда, как результат прогноза.
Алгоритм тестировали, преимущественно, на ряде Лоренца.
На данный момент рано говорить о том насколько он лучше или хуже. Похоже, что алгоритм подвержен нахождению псевдопериодов и с ростом уровня шума количество ложных периодов возрастает.
С другой стороны, при удачно подборе параметров точность прогноза достаточно высокая(отклонение до 7-10 процентов, что для хаотического ряда неплохо.)
К тестированию на реальных данным перейдем позже. Картинки постараюсь подготовить и добавить в ближайшее время.
Спасибо за внимание.


